
kubelet源码解析-启动流程与POD处理(上)
kubelet介绍
在k8s集群中的每个节点上都运行着一个kubelet服务进程,其主要负责向apiserver注册节点、管理pod及pod中的容器,并通过 cAdvisor 监控节点和容器的资源。
- 节点管理:节点注册、节点状态更新(定期心跳)
- pod管理:接受来自apiserver、file、http等PodSpec,并确保这些 PodSpec 中描述的容器处于运行状态且运行状况良好
- 容器健康检查:通过ReadinessProbe、LivenessProbe两种探针检查容器健康状态
- 资源监控:通过 cAdvisor 获取其所在节点及容器的监控数据
kubelet组件模块
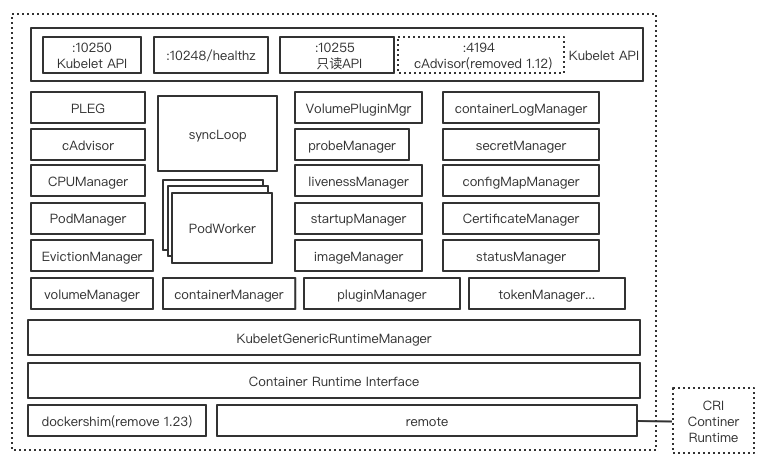
kubelet组件模块如上图所示,下面先对几个比较重要的几个模块进行简单说明:
- Pleg(Pod Lifecycle Event Generator) 是kubelet 的核心模块,PLEG周期性调用container runtime获取本节点containers/sandboxes的信息(像docker ps),并与自身维护的pods cache信息进行对比,生成对应的 PodLifecycleEvent并发送到plegCh中,在kubelet syncLoop中对plegCh进行消费处理,最终达到用户的期望状态,相关设计可以看这里
- podManager提供存储、访问Pod信息的接口,维护static pod和mirror pod的映射关系
- containerManager 管理容器的各种资源,比如 CGroups、QoS、cpuset、device 等
- KubeletGenericRuntimeManager是容器运行时的管理者,负责于 CRI 交互,完成容器和镜像的管理;关于client/server container runtime 设计可以看这里
- statusManager负责维护pod状态信息并负责同步到apiserver
- probeManager负责探测pod状态,依赖statusManager、statusManager、livenessManager、startupManager
- cAdvisor是google开源的容器监控工具,集成在kubelet中,收集节点与容器的监控信息,对外提供查询接口
- volumeManager 管理容器的存储卷,比如格式化资盘、挂载到 Node 本地、最后再将挂载路径传给容器
深入kubelet工作原理
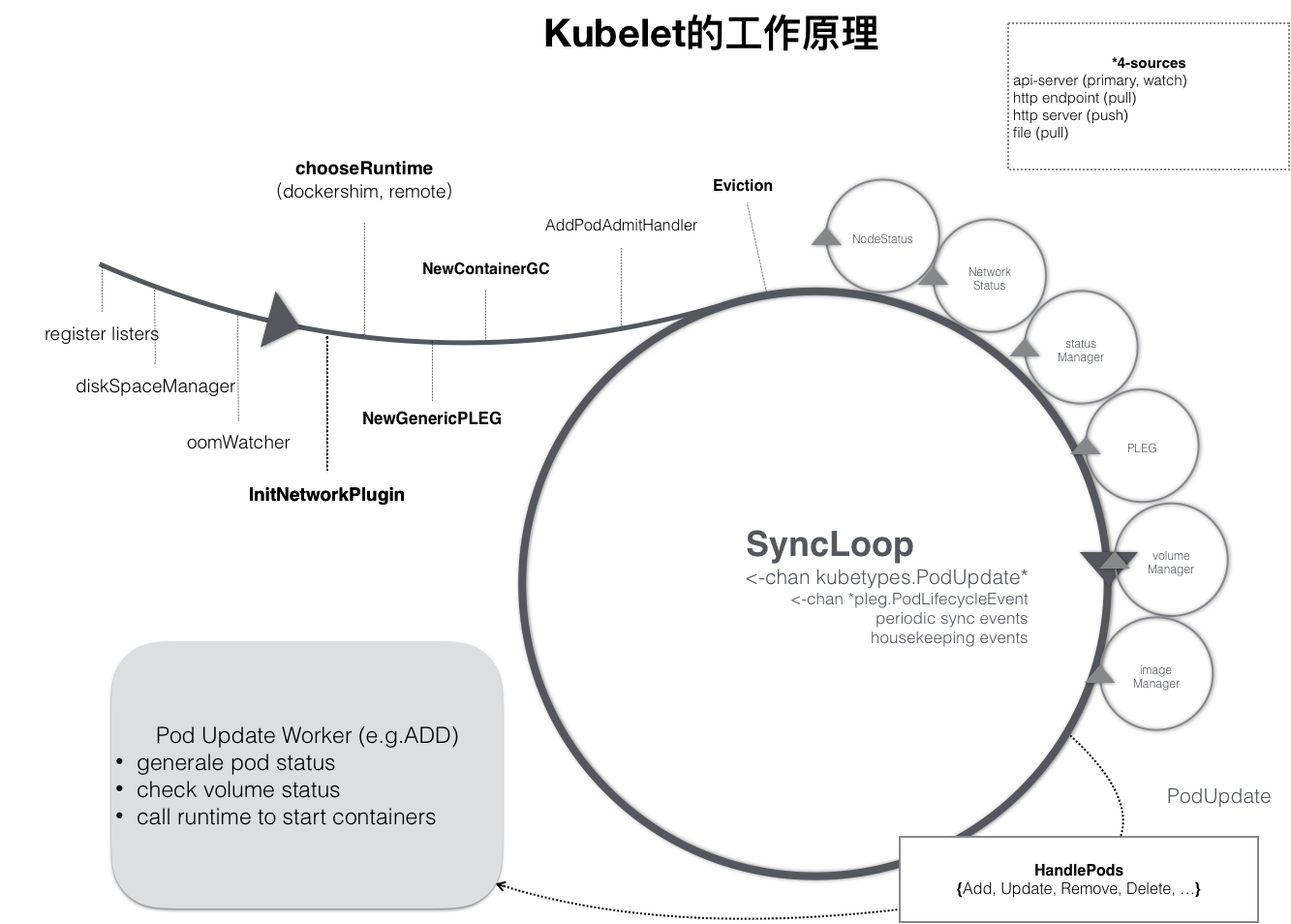
从上图可以看出kubelet的主要工作逻辑在SyncLoop控制循环中,处理pod更新事件、pod生命周期变化、周期sync事件、定时清理事件;SyncLoop旁还有处理其他逻辑的控制循环,例如处理pod状态同步的statusManager,处理健康检查的probeManager等。
下面将从kubelet源码来分析各个环节的处理逻辑。
kubelet代码(版本1.19)主要位于cmd/kubelet与pkg/kubelet下,首先看下kubelet启动流程与初始化
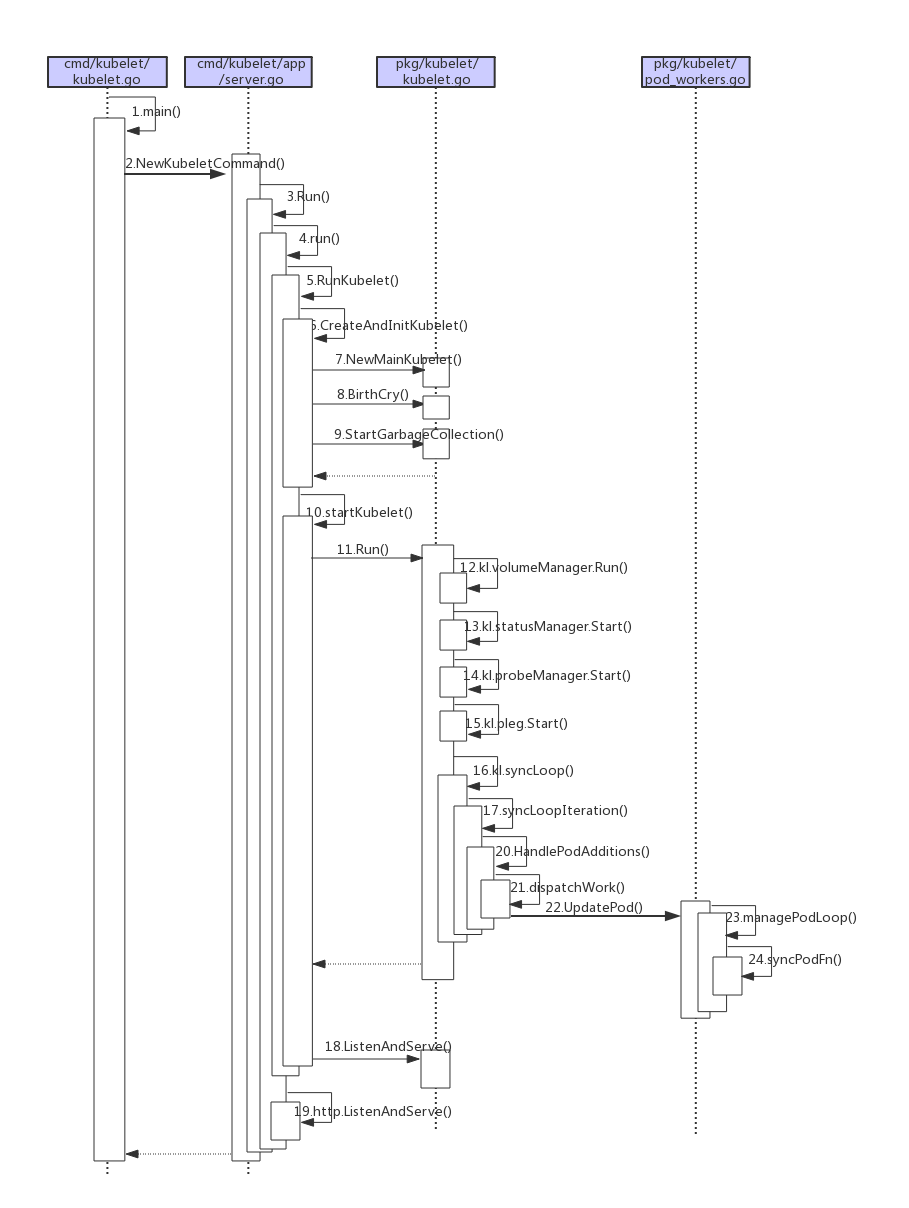
1 cmd/kubelet/kubelet.go:34
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewKubeletCommand()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
main 入口函数,kubelet依赖cobra命令行库,创建kubelet command并执行
2 cmd/kubelet/app/server.go:113
func NewKubeletCommand() *cobra.Command {
cleanFlagSet := pflag.NewFlagSet(componentKubelet, pflag.ContinueOnError)
cleanFlagSet.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
// kubelet包含两部分配置
// kubeletFlags是不能在运行时修改的配置或不在node间共享的配置
// kubeletConfig可以在node间共享的配置,可以动态配置
kubeletFlags := options.NewKubeletFlags()
kubeletConfig, err := options.NewKubeletConfiguration()
if err != nil {
klog.Fatal(err)
}
cmd := &cobra.Command{
Use: componentKubelet,
...
Run: func(cmd *cobra.Command, args []string) {
// 命令行参数解析
if err := cleanFlagSet.Parse(args); err != nil {
cmd.Usage()
klog.Fatal(err)
}
...
// 验证参数
if err := options.ValidateKubeletFlags(kubeletFlags); err != nil {
klog.Fatal(err)
}
// 加载kubelet配置文件
if configFile := kubeletFlags.KubeletConfigFile; len(configFile) > 0 {
kubeletConfig, err = loadConfigFile(configFile)
...
}
// 验证配置文件
if err := kubeletconfigvalidation.ValidateKubeletConfiguration(kubeletConfig); err != nil {
klog.Fatal(err)
}
// 构建KubeletServer
kubeletServer := &options.KubeletServer{
KubeletFlags: *kubeletFlags,
KubeletConfiguration: *kubeletConfig,
}
// 创建KubeletDeps
kubeletDeps, err := UnsecuredDependencies(kubeletServer, utilfeature.DefaultFeatureGate)
if err != nil {
klog.Fatal(err)
}
// 设置信号处理
ctx := genericapiserver.SetupSignalContext()
// 执行Run
klog.V(5).Infof("KubeletConfiguration: %#v", kubeletServer.KubeletConfiguration)
if err := Run(ctx, kubeletServer, kubeletDeps, utilfeature.DefaultFeatureGate); err != nil {
klog.Fatal(err)
}
},
}
......
return cmd
}
NewKubeletCommand创建kubelet cobra.Command结构体,Run函数主要解析参数、配置文件,构建KubeletServer、KubeletDependencies,设置信号处理函数,最后执行Run
3 cmd/kubelet/app/server.go:472
func run(ctx context.Context, s *options.KubeletServer, kubeDeps *kubelet.Dependencies, featureGate featuregate.FeatureGate) (err error) {
......
// 验证KubeletServer中flags、configs参数
if err := options.ValidateKubeletServer(s); err != nil {
return err
}
// 获得Kubelet Lock File,feature
if s.ExitOnLockContention && s.LockFilePath == "" {
return errors.New("cannot exit on lock file contention: no lock file specified")
}
done := make(chan struct{})
if s.LockFilePath != "" {
klog.Infof("acquiring file lock on %q", s.LockFilePath)
if err := flock.Acquire(s.LockFilePath); err != nil {
return fmt.Errorf("unable to acquire file lock on %q: %v", s.LockFilePath, err)
}
if s.ExitOnLockContention {
klog.Infof("watching for inotify events for: %v", s.LockFilePath)
if err := watchForLockfileContention(s.LockFilePath, done); err != nil {
return err
}
}
}
// 将当前配置注册到http server /configz URL
err = initConfigz(&s.KubeletConfiguration)
if err != nil {
klog.Errorf("unable to register KubeletConfiguration with configz, error: %v", err)
}
......
// 如果是standalone mode将所有client设置为nil
switch {
case standaloneMode:
kubeDeps.KubeClient = nil
kubeDeps.EventClient = nil
kubeDeps.HeartbeatClient = nil
klog.Warningf("standalone mode, no API client")
// 根据配置创建各个clientset
case kubeDeps.KubeClient == nil, kubeDeps.EventClient == nil, kubeDeps.HeartbeatClient == nil:
clientConfig, closeAllConns, err := buildKubeletClientConfig(ctx, s, nodeName)
if err != nil {
return err
}
if closeAllConns == nil {
return errors.New("closeAllConns must be a valid function other than nil")
}
kubeDeps.OnHeartbeatFailure = closeAllConns
kubeDeps.KubeClient, err = clientset.NewForConfig(clientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet client: %v", err)
}
// make a separate client for events
eventClientConfig := *clientConfig
eventClientConfig.QPS = float32(s.EventRecordQPS)
eventClientConfig.Burst = int(s.EventBurst)
kubeDeps.EventClient, err = v1core.NewForConfig(&eventClientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet event client: %v", err)
}
// make a separate client for heartbeat with throttling disabled and a timeout attached
heartbeatClientConfig := *clientConfig
heartbeatClientConfig.Timeout = s.KubeletConfiguration.NodeStatusUpdateFrequency.Duration
// The timeout is the minimum of the lease duration and status update frequency
leaseTimeout := time.Duration(s.KubeletConfiguration.NodeLeaseDurationSeconds) * time.Second
if heartbeatClientConfig.Timeout > leaseTimeout {
heartbeatClientConfig.Timeout = leaseTimeout
}
heartbeatClientConfig.QPS = float32(-1)
kubeDeps.HeartbeatClient, err = clientset.NewForConfig(&heartbeatClientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet heartbeat client: %v", err)
}
}
// 初始化auth
if kubeDeps.Auth == nil {
auth, runAuthenticatorCAReload, err := BuildAuth(nodeName, kubeDeps.KubeClient, s.KubeletConfiguration)
if err != nil {
return err
}
kubeDeps.Auth = auth
runAuthenticatorCAReload(ctx.Done())
}
// 设置cgroupRoot
var cgroupRoots []string
nodeAllocatableRoot := cm.NodeAllocatableRoot(s.CgroupRoot, s.CgroupsPerQOS, s.CgroupDriver)
cgroupRoots = append(cgroupRoots, nodeAllocatableRoot)
kubeletCgroup, err := cm.GetKubeletContainer(s.KubeletCgroups)
if err != nil {
klog.Warningf("failed to get the kubelet's cgroup: %v. Kubelet system container metrics may be missing.", err)
} else if kubeletCgroup != "" {
cgroupRoots = append(cgroupRoots, kubeletCgroup)
}
runtimeCgroup, err := cm.GetRuntimeContainer(s.ContainerRuntime, s.RuntimeCgroups)
if err != nil {
klog.Warningf("failed to get the container runtime's cgroup: %v. Runtime system container metrics may be missing.", err)
} else if runtimeCgroup != "" {
// RuntimeCgroups is optional, so ignore if it isn't specified
cgroupRoots = append(cgroupRoots, runtimeCgroup)
}
if s.SystemCgroups != "" {
// SystemCgroups is optional, so ignore if it isn't specified
cgroupRoots = append(cgroupRoots, s.SystemCgroups)
}
// 初始化cAdvisor
if kubeDeps.CAdvisorInterface == nil {
imageFsInfoProvider := cadvisor.NewImageFsInfoProvider(s.ContainerRuntime, s.RemoteRuntimeEndpoint)
kubeDeps.CAdvisorInterface, err = cadvisor.New(imageFsInfoProvider, s.RootDirectory, cgroupRoots, cadvisor.UsingLegacyCadvisorStats(s.ContainerRuntime, s.RemoteRuntimeEndpoint))
if err != nil {
return err
}
}
// Setup event recorder if required.
makeEventRecorder(kubeDeps, nodeName)
// 初始化containerManager
if kubeDeps.ContainerManager == nil {
if s.CgroupsPerQOS && s.CgroupRoot == "" {
klog.Info("--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /")
s.CgroupRoot = "/"
}
// 计算节点capacity
var reservedSystemCPUs cpuset.CPUSet
var errParse error
if s.ReservedSystemCPUs != "" {
reservedSystemCPUs, errParse = cpuset.Parse(s.ReservedSystemCPUs)
if errParse != nil {
// invalid cpu list is provided, set reservedSystemCPUs to empty, so it won't overwrite kubeReserved/systemReserved
klog.Infof("Invalid ReservedSystemCPUs \"%s\"", s.ReservedSystemCPUs)
return errParse
}
// is it safe do use CAdvisor here ??
machineInfo, err := kubeDeps.CAdvisorInterface.MachineInfo()
if err != nil {
// if can't use CAdvisor here, fall back to non-explicit cpu list behavor
klog.Warning("Failed to get MachineInfo, set reservedSystemCPUs to empty")
reservedSystemCPUs = cpuset.NewCPUSet()
} else {
reservedList := reservedSystemCPUs.ToSlice()
first := reservedList[0]
last := reservedList[len(reservedList)-1]
if first < 0 || last >= machineInfo.NumCores {
// the specified cpuset is outside of the range of what the machine has
klog.Infof("Invalid cpuset specified by --reserved-cpus")
return fmt.Errorf("Invalid cpuset %q specified by --reserved-cpus", s.ReservedSystemCPUs)
}
}
} else {
reservedSystemCPUs = cpuset.NewCPUSet()
}
if reservedSystemCPUs.Size() > 0 {
// at cmd option valication phase it is tested either --system-reserved-cgroup or --kube-reserved-cgroup is specified, so overwrite should be ok
klog.Infof("Option --reserved-cpus is specified, it will overwrite the cpu setting in KubeReserved=\"%v\", SystemReserved=\"%v\".", s.KubeReserved, s.SystemReserved)
if s.KubeReserved != nil {
delete(s.KubeReserved, "cpu")
}
if s.SystemReserved == nil {
s.SystemReserved = make(map[string]string)
}
s.SystemReserved["cpu"] = strconv.Itoa(reservedSystemCPUs.Size())
klog.Infof("After cpu setting is overwritten, KubeReserved=\"%v\", SystemReserved=\"%v\"", s.KubeReserved, s.SystemReserved)
}
kubeReserved, err := parseResourceList(s.KubeReserved)
if err != nil {
return err
}
systemReserved, err := parseResourceList(s.SystemReserved)
if err != nil {
return err
}
var hardEvictionThresholds []evictionapi.Threshold
// If the user requested to ignore eviction thresholds, then do not set valid values for hardEvictionThresholds here.
if !s.ExperimentalNodeAllocatableIgnoreEvictionThreshold {
hardEvictionThresholds, err = eviction.ParseThresholdConfig([]string{}, s.EvictionHard, nil, nil, nil)
if err != nil {
return err
}
}
experimentalQOSReserved, err := cm.ParseQOSReserved(s.QOSReserved)
if err != nil {
return err
}
devicePluginEnabled := utilfeature.DefaultFeatureGate.Enabled(features.DevicePlugins)
// 创建ContainerManager,其中包含cgroupManager、QosContainerManager、cpuManager等
kubeDeps.ContainerManager, err = cm.NewContainerManager(
kubeDeps.Mounter,
kubeDeps.CAdvisorInterface,
cm.NodeConfig{
RuntimeCgroupsName: s.RuntimeCgroups,
SystemCgroupsName: s.SystemCgroups,
KubeletCgroupsName: s.KubeletCgroups,
ContainerRuntime: s.ContainerRuntime,
CgroupsPerQOS: s.CgroupsPerQOS,
CgroupRoot: s.CgroupRoot,
CgroupDriver: s.CgroupDriver,
KubeletRootDir: s.RootDirectory,
ProtectKernelDefaults: s.ProtectKernelDefaults,
NodeAllocatableConfig: cm.NodeAllocatableConfig{
KubeReservedCgroupName: s.KubeReservedCgroup,
SystemReservedCgroupName: s.SystemReservedCgroup,
EnforceNodeAllocatable: sets.NewString(s.EnforceNodeAllocatable...),
KubeReserved: kubeReserved,
SystemReserved: systemReserved,
ReservedSystemCPUs: reservedSystemCPUs,
HardEvictionThresholds: hardEvictionThresholds,
},
QOSReserved: *experimentalQOSReserved,
ExperimentalCPUManagerPolicy: s.CPUManagerPolicy,
ExperimentalCPUManagerReconcilePeriod: s.CPUManagerReconcilePeriod.Duration,
ExperimentalPodPidsLimit: s.PodPidsLimit,
EnforceCPULimits: s.CPUCFSQuota,
CPUCFSQuotaPeriod: s.CPUCFSQuotaPeriod.Duration,
ExperimentalTopologyManagerPolicy: s.TopologyManagerPolicy,
},
s.FailSwapOn,
devicePluginEnabled,
kubeDeps.Recorder)
if err != nil {
return err
}
}
// 检查是否root启动
if err := checkPermissions(); err != nil {
klog.Error(err)
}
utilruntime.ReallyCrash = s.ReallyCrashForTesting
// kubelet oom分数设置
oomAdjuster := kubeDeps.OOMAdjuster
if err := oomAdjuster.ApplyOOMScoreAdj(0, int(s.OOMScoreAdj)); err != nil {
klog.Warning(err)
}
// 初始化kubeDeps中runtimeService、runtimeImageService,如果是docker启动dockershim
err = kubelet.PreInitRuntimeService(&s.KubeletConfiguration,
kubeDeps, &s.ContainerRuntimeOptions,
s.ContainerRuntime,
s.RuntimeCgroups,
s.RemoteRuntimeEndpoint,
s.RemoteImageEndpoint,
s.NonMasqueradeCIDR)
if err != nil {
return err
}
// 执行下一步RunKubelet
if err := RunKubelet(s, kubeDeps, s.RunOnce); err != nil {
return err
}
// 启动healthz http server
if s.HealthzPort > 0 {
mux := http.NewServeMux()
healthz.InstallHandler(mux)
go wait.Until(func() {
err := http.ListenAndServe(net.JoinHostPort(s.HealthzBindAddress, strconv.Itoa(int(s.HealthzPort))), mux)
if err != nil {
klog.Errorf("Starting healthz server failed: %v", err)
}
}, 5*time.Second, wait.NeverStop)
}
if s.RunOnce {
return nil
}
// 通知systemd
go daemon.SdNotify(false, "READY=1")
select {
case <-done:
break
case <-ctx.Done():
break
}
return nil
}
run 主要执行配置检查与初始化工作
- KubeletServer参数验证
- KubeDependencies中各种clientset初始化
- ContainerManager创建初始化
- 启动dockershim、创建runtimeService、runtimeImageService
4 cmd/kubelet/app/server.go:1071
func RunKubelet(kubeServer *options.KubeletServer, kubeDeps *kubelet.Dependencies, runOnce bool) error {
hostname, err := nodeutil.GetHostname(kubeServer.HostnameOverride)
if err != nil {
return err
}
// Query the cloud provider for our node name, default to hostname if kubeDeps.Cloud == nil
nodeName, err := getNodeName(kubeDeps.Cloud, hostname)
if err != nil {
return err
}
hostnameOverridden := len(kubeServer.HostnameOverride) > 0
// Setup event recorder if required.
makeEventRecorder(kubeDeps, nodeName)
// 特权模式启动
capabilities.Initialize(capabilities.Capabilities{
AllowPrivileged: true,
})
credentialprovider.SetPreferredDockercfgPath(kubeServer.RootDirectory)
klog.V(2).Infof("Using root directory: %v", kubeServer.RootDirectory)
if kubeDeps.OSInterface == nil {
kubeDeps.OSInterface = kubecontainer.RealOS{}
}
// 创建初始化Kubelet结构体
k, err := createAndInitKubelet(&kubeServer.KubeletConfiguration,
......
kubeServer.NodeStatusMaxImages)
if err != nil {
return fmt.Errorf("failed to create kubelet: %v", err)
}
// NewMainKubelet should have set up a pod source config if one didn't exist
// when the builder was run. This is just a precaution.
if kubeDeps.PodConfig == nil {
return fmt.Errorf("failed to create kubelet, pod source config was nil")
}
podCfg := kubeDeps.PodConfig
if err := rlimit.SetNumFiles(uint64(kubeServer.MaxOpenFiles)); err != nil {
klog.Errorf("Failed to set rlimit on max file handles: %v", err)
}
// process pods and exit.
if runOnce {
if _, err := k.RunOnce(podCfg.Updates()); err != nil {
return fmt.Errorf("runonce failed: %v", err)
}
klog.Info("Started kubelet as runonce")
} else {
// 调用startKubelet
startKubelet(k, podCfg, &kubeServer.KubeletConfiguration, kubeDeps, kubeServer.EnableCAdvisorJSONEndpoints, kubeServer.EnableServer)
klog.Info("Started kubelet")
}
return nil
}
RunKubelet 创建Kubelet关键结构体,执行startKubelet,其最终通过goroutine进入Kubelet.Run
5 cmd/kubelet/kubelet.go:333
由于Kubelet结构体非常关键,先看下NewMainKubelet创建初始化Kubelet关键结构体函数
func createAndInitKubelet(kubeCfg *kubeletconfiginternal.KubeletConfiguration,
......
nodeStatusMaxImages int32) (k kubelet.Bootstrap, err error) {
// 创建初始化Kubelet
k, err = kubelet.NewMainKubelet(kubeCfg,
......
nodeStatusMaxImages)
if err != nil {
return nil, err
}
// 向apiserver发送kubelet启动event
k.BirthCry()
// 启动垃圾回收container、images
k.StartGarbageCollection()
return k, nil
}
func NewMainKubelet(...){
......
// 创建PodConfig,watch apiserver、file、http等
if kubeDeps.PodConfig == nil {
var err error
kubeDeps.PodConfig, err = makePodSourceConfig(kubeCfg, kubeDeps, nodeName)
if err != nil {
return nil, err
}
}
......
// 创建service informer、node、oom watcher
var serviceLister corelisters.ServiceLister
var serviceHasSynced cache.InformerSynced
if kubeDeps.KubeClient != nil {
kubeInformers := informers.NewSharedInformerFactory(kubeDeps.KubeClient, 0)
serviceLister = kubeInformers.Core().V1().Services().Lister()
serviceHasSynced = kubeInformers.Core().V1().Services().Informer().HasSynced
kubeInformers.Start(wait.NeverStop)
} else {
serviceIndexer := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})
serviceLister = corelisters.NewServiceLister(serviceIndexer)
serviceHasSynced = func() bool { return true }
}
nodeIndexer := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{})
if kubeDeps.KubeClient != nil {
fieldSelector := fields.Set{api.ObjectNameField: string(nodeName)}.AsSelector()
nodeLW := cache.NewListWatchFromClient(kubeDeps.KubeClient.CoreV1().RESTClient(), "nodes", metav1.NamespaceAll, fieldSelector)
r := cache.NewReflector(nodeLW, &v1.Node{}, nodeIndexer, 0)
go r.Run(wait.NeverStop)
}
nodeLister := corelisters.NewNodeLister(nodeIndexer)
nodeRef := &v1.ObjectReference{
Kind: "Node",
Name: string(nodeName),
UID: types.UID(nodeName),
Namespace: "",
}
oomWatcher, err := oomwatcher.NewWatcher(kubeDeps.Recorder)
if err != nil {
return nil, err
}
// 创建Kubelet
klet := &Kubelet{...}
// 创建各种manager例如secret、configMap
// 创建podManager,管理pod信息
klet.podManager = kubepod.NewBasicPodManager(mirrorPodClient, secretManager, configMapManager)
// 创建runtimeManager,其通过runtimeService、runtimeImageService实现对container的管理
runtime, err := kuberuntime.NewKubeGenericRuntimeManager(...)
// 创建pleg
klet.pleg = pleg.NewGenericPLEG(klet.containerRuntime, plegChannelCapacity, plegRelistPeriod, klet.podCache, clock.RealClock{})
// imageManager、probeManager、volumeManager、pluginManager等设置
// 初始化workQueue、podWorker
klet.reasonCache = NewReasonCache()
klet.workQueue = queue.NewBasicWorkQueue(klet.clock)
// 创建podWorker,syncPod为每个pod处理逻辑函数,在每个pod的goroutine中对pod更新进行同步
klet.podWorkers = newPodWorkers(klet.syncPod, kubeDeps.Recorder, klet.workQueue, klet.resyncInterval, backOffPeriod, klet.podCache)
......
}
NewMainKubelet 创建并初始化Kubelet结构体,其依赖各种Manager、podConfig、pleg、podWorkers的初始化
6 pkg/kubelet/kubelet.go:1314 Kubelet.Run方法
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
// 初始化与runtime无关的逻辑,metrics、imageManager等
if err := kl.initializeModules(); err != nil {
kl.recorder.Eventf(kl.nodeRef, v1.EventTypeWarning, events.KubeletSetupFailed, err.Error())
klog.Fatal(err)
}
// 启动volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
if kl.kubeClient != nil {
// 同步node状态
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
// 启动node lease
go kl.nodeLeaseController.Run(wait.NeverStop)
}
// runtime首次初始化、定时更新
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// 设置iptables规则
if kl.makeIPTablesUtilChains {
kl.initNetworkUtil()
}
// 启动podKiller,监听podKiller.podKillingCh
go wait.Until(kl.podKiller.PerformPodKillingWork, 1*time.Second, wait.NeverStop)
// 启动statusManager、probeManager
kl.statusManager.Start()
kl.probeManager.Start()
// Start syncing RuntimeClasses if enabled.
if kl.runtimeClassManager != nil {
kl.runtimeClassManager.Start(wait.NeverStop)
}
// 启动pleg
kl.pleg.Start()
// 进入主循环
kl.syncLoop(updates, kl)
}
Run 实现kubelet参数、配置、信号处理注册,初始化依赖、Kubelet启动Manager, 进入各自manager处理逻辑,最后进入kubelet主循环逻辑,主循环有5个事件源
- configCh podConfig处理来自apiserver、file、http的pod更新,在创建Kubelet时初始化
- handler liveness manager处理,在创建Kubelet时初始化,为statusManager的一部分
- syncCh time定时同步pod
- housekeepingCh time定时清理pod
- plegCh 处理来自pleg的消息,在创建Kubelet时初始化,关于pleg可以看这里,简单说对容器状态感知由每个pod worker(goroutine)轮询改为pleg
7 pkg/kubelet/kubelet.go:1814 kubelet事件循环函数
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
// 处理来自apiserver、file、http的pod增删改查,最终走到Kubelet的syncPod处理
case u, open := <-configCh:
if !open {
klog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
klog.Errorf("Kubelet does not support snapshot update")
default:
klog.Errorf("Invalid event type received: %d.", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
// 处理来自runtime的容器变化
case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
klog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
// 同步pod状态,最终走到Kubelet的syncPod处理
case <-syncCh:
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
klog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
// 处理probe fail,最终走到Kubelet的syncPod处理
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
klog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
klog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
klog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
klog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
klog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}
syncLoopIteration 根据事件类型调用对应的handler进行处理
8 pkg/kubelet/pod_workers.go:200
对不同事件有不同的处理handler,大部分handler都会通过dispatchWork进入podWorkers.UpdatePod
// podWorkers存储每个pod的goroutine并处理pod的update到对应goroutine
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
// pod是否已存在,如果不存在则创建channel,启动对应pod的goroutine
if podUpdates, exists = p.podUpdates[uid]; !exists {
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
go func() {
defer runtime.HandleCrash()
// pod处理函数
p.managePodLoop(podUpdates)
}()
}
// pod存在且空闲则写入,否则暂存最近的更新
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// SyncPodKill不会被覆盖
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}
// pod的处理goroutine,监听事件并调用Kubelet的方法syncPod处理
pkg/kubelet/pod_workers.go:158
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
// 调用Kubelet的方法syncPod
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
// 查看lastUndeliveredWorkUpdate是否有未处理的事件,继续处理
p.wrapUp(update.Pod.UID, err)
}
}
9 pkg/kubelet/kubelet.go:1395
syncPod: 在交由runtimeManager完成真正的处理逻辑之前,进行一些预处理
func (kl *Kubelet) syncPod(o syncPodOptions) error {
pod := o.pod
mirrorPod := o.mirrorPod
podStatus := o.podStatus
updateType := o.updateType
// 处理kill Pod
if updateType == kubetypes.SyncPodKill {
killPodOptions := o.killPodOptions
if killPodOptions == nil || killPodOptions.PodStatusFunc == nil {
return fmt.Errorf("kill pod options are required if update type is kill")
}
apiPodStatus := killPodOptions.PodStatusFunc(pod, podStatus)
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// we kill the pod with the specified grace period since this is a termination
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
....
// 是否能运行pod
runnable := kl.canRunPod(pod)
if !runnable.Admit {
//不能回写container等待原因
apiPodStatus.Reason = runnable.Reason
apiPodStatus.Message = runnable.Message
// Waiting containers are not creating.
const waitingReason = "Blocked"
for _, cs := range apiPodStatus.InitContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
for _, cs := range apiPodStatus.ContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
}
// 更新statusManager pod状态
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// 校验失败、标记删除、pod失败则kill pod
if !runnable.Admit || pod.DeletionTimestamp != nil || apiPodStatus.Phase == v1.PodFailed {
var syncErr error
if err := kl.killPod(pod, nil, podStatus, nil); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
if !runnable.Admit {
// There was no error killing the pod, but the pod cannot be run.
// Return an error to signal that the sync loop should back off.
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
}
return syncErr
}
// network plugin是否ready
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
// pod crgoup创建
pcm := kl.containerManager.NewPodContainerManager()
// 检查pod是否已经Terminate
if !kl.podIsTerminated(pod) {
// When the kubelet is restarted with the cgroups-per-qos
// flag enabled, all the pod's running containers
// should be killed intermittently and brought back up
// under the qos cgroup hierarchy.
// Check if this is the pod's first sync
firstSync := true
for _, containerStatus := range apiPodStatus.ContainerStatuses {
if containerStatus.State.Running != nil {
firstSync = false
break
}
}
// Don't kill containers in pod if pod's cgroups already
// exists or the pod is running for the first time
podKilled := false
if !pcm.Exists(pod) && !firstSync {
if err := kl.killPod(pod, nil, podStatus, nil); err == nil {
podKilled = true
}
}
// Create and Update pod's Cgroups
// Don't create cgroups for run once pod if it was killed above
// The current policy is not to restart the run once pods when
// the kubelet is restarted with the new flag as run once pods are
// expected to run only once and if the kubelet is restarted then
// they are not expected to run again.
// We don't create and apply updates to cgroup if its a run once pod and was killed above
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
if err := pcm.EnsureExists(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToCreatePodContainer, "unable to ensure pod container exists: %v", err)
return fmt.Errorf("failed to ensure that the pod: %v cgroups exist and are correctly applied: %v", pod.UID, err)
}
}
}
}
// 如果是mirrorPod进入mirrorPod处理逻辑
if kubetypes.IsStaticPod(pod) {
podFullName := kubecontainer.GetPodFullName(pod)
deleted := false
if mirrorPod != nil {
if mirrorPod.DeletionTimestamp != nil || !kl.podManager.IsMirrorPodOf(mirrorPod, pod) {
// The mirror pod is semantically different from the static pod. Remove
// it. The mirror pod will get recreated later.
klog.Infof("Trying to delete pod %s %v", podFullName, mirrorPod.ObjectMeta.UID)
var err error
deleted, err = kl.podManager.DeleteMirrorPod(podFullName, &mirrorPod.ObjectMeta.UID)
if deleted {
klog.Warningf("Deleted mirror pod %q because it is outdated", format.Pod(mirrorPod))
} else if err != nil {
klog.Errorf("Failed deleting mirror pod %q: %v", format.Pod(mirrorPod), err)
}
}
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
klog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}
// 准备pod文件目录
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// 等待挂载volumes
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// 调用runtimeManager处理pod
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}