
kube-scheduler源码解析
kube-scheduler设计
scheduler作为k8s的核心组件之一,其功能为每个Pod选择一个合适的node,其流程分为3步,首先获得未调度podList,然后通过一系列调度算法为Pod选择合适的node,将数据发送到apiserver。调度算法主要包含两部分predicates(预选) 和 priorities(优选),最后将评分最高的node更新到Pod
For given pod:
+---------------------------------------------+
| Schedulable nodes: |
| |
| +--------+ +--------+ +--------+ |
| | node 1 | | node 2 | | node 3 | |
| +--------+ +--------+ +--------+ |
| |
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
Pred. filters: node 3 doesn't have enough resource
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
| remaining nodes: |
| +--------+ +--------+ |
| | node 1 | | node 2 | |
| +--------+ +--------+ |
| |
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
Priority function: node 1: p=2
node 2: p=5
+-------------------+-------------------------+
|
|
v
select max{node priority} = node 2
scheduler支持的两种扩展方式
- Extender 外部扩展机制,不够灵活、效率低,调用位置固定
- Framework 内部扩展机制,通过调度插件(plugins)实现,调度插件通过实现一个或多个扩展点(extension-point)来提供调度行为,实现在scheduler二进制中效率高,具体设计见这里,下图=>即为扩展点(前面是串行,后面bind阶段为并发),默认调度插件见这里
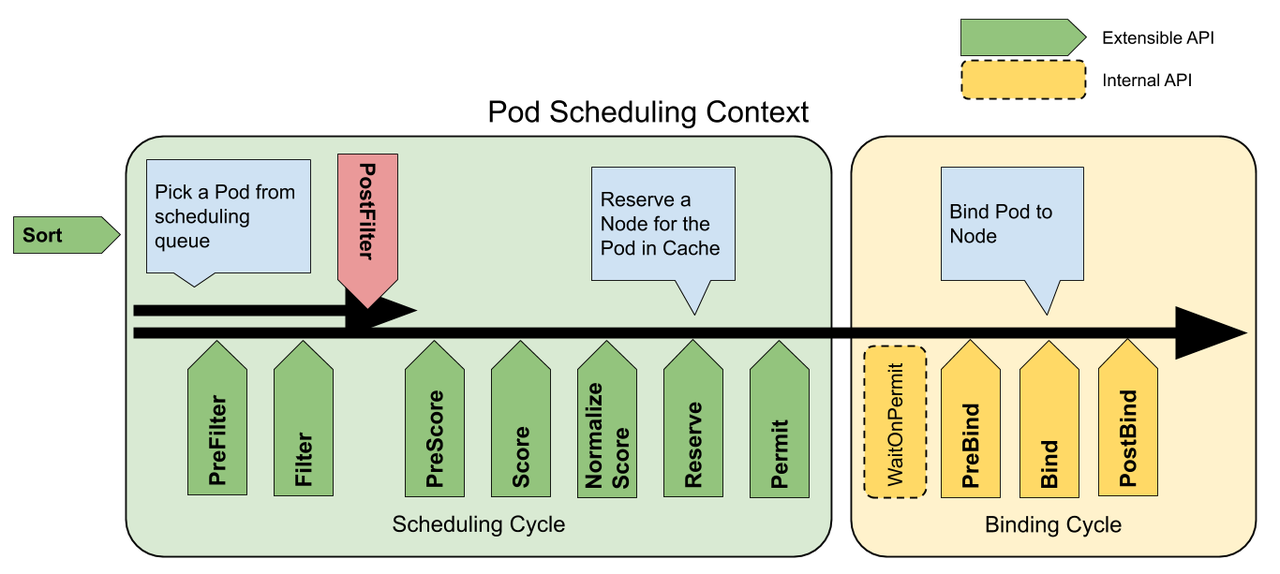
scheduler支持多配置文件(profiles),不同profile可以配置不同的调度插件(enable/disabled)及其顺序,Pod未指明调度器名称时使用默认为default-scheduler,具体配置见这里
源码分析
k8s中所有组件的启动流程都是类似的,首先会解析命令行参数、添加默认值,然后执行run方法执行主逻辑,下面看下scheduler的代码
cmd/kube-scheduler/app/server.go:120
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 根据参数生成config并初始化、构建scheduler
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
if len(opts.WriteConfigTo) > 0 {
if err := options.WriteConfigFile(opts.WriteConfigTo, &cc.ComponentConfig); err != nil {
return err
}
klog.Infof("Wrote configuration to: %s\n", opts.WriteConfigTo)
return nil
}
return Run(ctx, cc, sched)
}
runCommand主要完成:
- 参数验证
- 调用Setup,根据参数构建、初始化config、scheduler
- 执行Run
cmd/kube-scheduler/app/server.go:295 先看下Setup函数和创建的informer
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// 创建kube client、eventBroadcast、informer构建
c, err := opts.Config()
if err != nil {
return nil, nil, err
}
// 构建completed config,填充默认配置
cc := c.Complete()
// 加载outOfTreeRegistry,默认没有
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
// 创建scheduler
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.PodInformer,
recorderFactory,
ctx.Done(),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
)
if err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
pkg/scheduler/factory.go:432
// 获取非terminating的pod
func NewPodInformer(client clientset.Interface, resyncPeriod time.Duration) coreinformers.PodInformer {
selector := fields.ParseSelectorOrDie(
"status.phase!=" + string(v1.PodSucceeded) +
",status.phase!=" + string(v1.PodFailed))
lw := cache.NewListWatchFromClient(client.CoreV1().RESTClient(), string(v1.ResourcePods), metav1.NamespaceAll, selector)
return &podInformer{
informer: cache.NewSharedIndexInformer(lw, &v1.Pod{}, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}),
}
}
Setup函数主要完成
- 验证参数
- 根据参数创建CompletedConfig(会初始化kube client、eventBroadcaster、informers)
- 调用scheduler.New创建scheduler
pkg/scheduler/scheduler.go:186 scheduler.New
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
podInformer coreinformers.PodInformer,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
// 将配置文件中的配置赋值到默认配置值
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
// 初始化schedulerCache
schedulerCache := internalcache.New(30*time.Second, stopEverything)
// plugins初始化,是调度插件名称及其构造函数的map
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
// 初始化snapshot,通过map保存node信息
snapshot := internalcache.NewEmptySnapshot()
// 创建配置
configurator := &Configurator{
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
podInformer: podInformer,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
// 多调度器
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
}
metrics.Register()
var sched *Scheduler
source := options.schedulerAlgorithmSource
// 创建scheduler
switch {
case source.Provider != nil:
// 使用默认DefaultProvider创建
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// 通过配置中的policy创建,已弃用
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
if err := initPolicyFromFile(source.Policy.File.Path, policy); err != nil {
return nil, err
}
case source.Policy.ConfigMap != nil:
if err := initPolicyFromConfigMap(client, source.Policy.ConfigMap, policy); err != nil {
return nil, err
}
}
// Set extenders on the configurator now that we've decoded the policy
// In this case, c.extenders should be nil since we're using a policy (and therefore not componentconfig,
// which would have set extenders in the above instantiation of Configurator from CC options)
configurator.extenders = policy.Extenders
sc, err := configurator.createFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
sched = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
sched.StopEverything = stopEverything
sched.client = client
sched.scheduledPodsHasSynced = podInformer.Informer().HasSynced
// 添加event handlers
addAllEventHandlers(sched, informerFactory, podInformer)
return sched, nil
}
scheduler.New主要完成
- configurator创建
- scheduler创建
- 添加eventHandler
具体创建scheduler代码如下,看下DefaultProvider的情况
func (c *Configurator) createFromProvider(providerName string) (*Scheduler, error) {
klog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
r := algorithmprovider.NewRegistry()
// 获得DefaultProvider默认plugins, 见pkg/scheduler/algorithmprovider/registry.go:78
defaultPlugins, exist := r[providerName]
if !exist {
return nil, fmt.Errorf("algorithm provider %q is not registered", providerName)
}
// 设置各个调度配置profile的plugins初始化
for i := range c.profiles {
prof := &c.profiles[i]
plugins := &schedulerapi.Plugins{}
plugins.Append(defaultPlugins)
plugins.Apply(prof.Plugins)
prof.Plugins = plugins
}
return c.create()
}
// create a scheduler from a set of registered plugins.
func (c *Configurator) create() (*Scheduler, error) {
var extenders []framework.Extender
var ignoredExtendedResources []string
// extender初始化
if len(c.extenders) != 0 {
var ignorableExtenders []framework.Extender
for ii := range c.extenders {
klog.V(2).Infof("Creating extender with config %+v", c.extenders[ii])
extender, err := core.NewHTTPExtender(&c.extenders[ii])
if err != nil {
return nil, err
}
if !extender.IsIgnorable() {
extenders = append(extenders, extender)
} else {
ignorableExtenders = append(ignorableExtenders, extender)
}
for _, r := range c.extenders[ii].ManagedResources {
if r.IgnoredByScheduler {
ignoredExtendedResources = append(ignoredExtendedResources, r.Name)
}
}
}
// place ignorable extenders to the tail of extenders
extenders = append(extenders, ignorableExtenders...)
}
// If there are any extended resources found from the Extenders, append them to the pluginConfig for each profile.
// This should only have an effect on ComponentConfig v1beta1, where it is possible to configure Extenders and
// plugin args (and in which case the extender ignored resources take precedence).
// For earlier versions, using both policy and custom plugin config is disallowed, so this should be the only
// plugin config for this plugin.
if len(ignoredExtendedResources) > 0 {
for i := range c.profiles {
prof := &c.profiles[i]
pc := schedulerapi.PluginConfig{
Name: noderesources.FitName,
Args: &schedulerapi.NodeResourcesFitArgs{
IgnoredResources: ignoredExtendedResources,
},
}
prof.PluginConfig = append(prof.PluginConfig, pc)
}
}
// The nominator will be passed all the way to framework instantiation.
nominator := internalqueue.NewPodNominator()
// profiles初始化,是调度器的Map,每个调度器都包含framework来管理plugins
profiles, err := profile.NewMap(c.profiles, c.buildFramework, c.recorderFactory,
frameworkruntime.WithPodNominator(nominator))
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
// Profiles are required to have equivalent queue sort plugins.
lessFn := profiles[c.profiles[0].SchedulerName].Framework.QueueSortFunc()
// 调度队列,优先队列
podQueue := internalqueue.NewSchedulingQueue(
lessFn,
internalqueue.WithPodInitialBackoffDuration(time.Duration(c.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(c.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
)
// Setup cache debugger.
debugger := cachedebugger.New(
c.informerFactory.Core().V1().Nodes().Lister(),
c.podInformer.Lister(),
c.schedulerCache,
podQueue,
)
debugger.ListenForSignal(c.StopEverything)
// 初始化algo
algo := core.NewGenericScheduler(
c.schedulerCache,
c.nodeInfoSnapshot,
extenders,
c.informerFactory.Core().V1().PersistentVolumeClaims().Lister(),
c.disablePreemption,
c.percentageOfNodesToScore,
)
return &Scheduler{
SchedulerCache: c.schedulerCache,
Algorithm: algo,
Profiles: profiles,
NextPod: internalqueue.MakeNextPodFunc(podQueue),
Error: MakeDefaultErrorFunc(c.client, c.informerFactory.Core().V1().Pods().Lister(), podQueue, c.schedulerCache),
StopEverything: c.StopEverything,
SchedulingQueue: podQueue,
}, nil
}
scheduler的创建主要包括:externder、多调度器、framework、调度队列、algo的初始化
scheduler创建完毕后调用addAllEventHandlers增加eventHandler,其接受者包含SchedulerCache 和 SchedulingQueue,前者是为了跟踪集群的资源和已调度 Pod 的状态,后者主要是给没有调度的 Pod 入队到 activeQ 中,如果是未调度的pod,会经过 event 的过滤器,其中 assignedPod(t) 会看 pod.Spec.NodeName 判断 pod 是不是已经调度或者 assume 了,responsibleForPod(t, sched.Profiles) 会看 pod.Spec.SchedulerName 看一下调度器名字是不是本调度器
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
podInformer coreinformers.PodInformer,
) {
// scheduled pod cache
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedPod(t)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return assignedPod(pod)
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
)
// unscheduled pod queue
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return !assignedPod(t) && responsibleForPod(t, sched.Profiles)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return !assignedPod(pod) && responsibleForPod(pod, sched.Profiles)
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
)
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
)
if utilfeature.DefaultFeatureGate.Enabled(features.CSINodeInfo) {
informerFactory.Storage().V1().CSINodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onCSINodeAdd,
UpdateFunc: sched.onCSINodeUpdate,
},
)
}
informerFactory.Core().V1().PersistentVolumes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
// MaxPDVolumeCountPredicate: since it relies on the counts of PV.
AddFunc: sched.onPvAdd,
UpdateFunc: sched.onPvUpdate,
},
)
informerFactory.Core().V1().PersistentVolumeClaims().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onPvcAdd,
UpdateFunc: sched.onPvcUpdate,
},
)
informerFactory.Core().V1().Services().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onServiceAdd,
UpdateFunc: sched.onServiceUpdate,
DeleteFunc: sched.onServiceDelete,
},
)
informerFactory.Storage().V1().StorageClasses().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onStorageClassAdd,
},
)
}
// 已调度节pod
func assignedPod(pod *v1.Pod) bool {
return len(pod.Spec.NodeName) != 0
}
// 判断调度器是否本调度器
func responsibleForPod(pod *v1.Pod, profiles profile.Map) bool {
return profiles.HandlesSchedulerName(pod.Spec.SchedulerName)
}
看下调度队列结构体,其包含3个队列 - activeQ 待调度队列 - podBackoffQ 调度失败待重试队列,即backoff机制 - unschedulableQ 不可调度队列
type PriorityQueue struct {
...
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
activeQ *heap.Heap
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
podBackoffQ *heap.Heap
// unschedulableQ holds pods that have been tried and determined unschedulable.
unschedulableQ *UnschedulablePodsMap
...
}
完成scheduler的初始化,调用Run
cmd/kube-scheduler/app/server.go:144
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// To help debugging, immediately log version
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
// Configz registration.
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// 启动event broadcaster.
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
// Setup healthz checks.
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
// 启动http server
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, false, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh returned by c.SecureServing.Serve
if _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// 启动所有informers
go cc.PodInformer.Informer().Run(ctx.Done())
cc.InformerFactory.Start(ctx.Done())
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// leader选举
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: sched.Run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so runCommand inline until done.
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
Run函数主要完成
- eventBroadcast启动
- Http server启动
- informers启动
- 选主
- 调用scheduler.Run
在进一步深入调度逻辑之前,先大概看下scheduler的执行逻辑
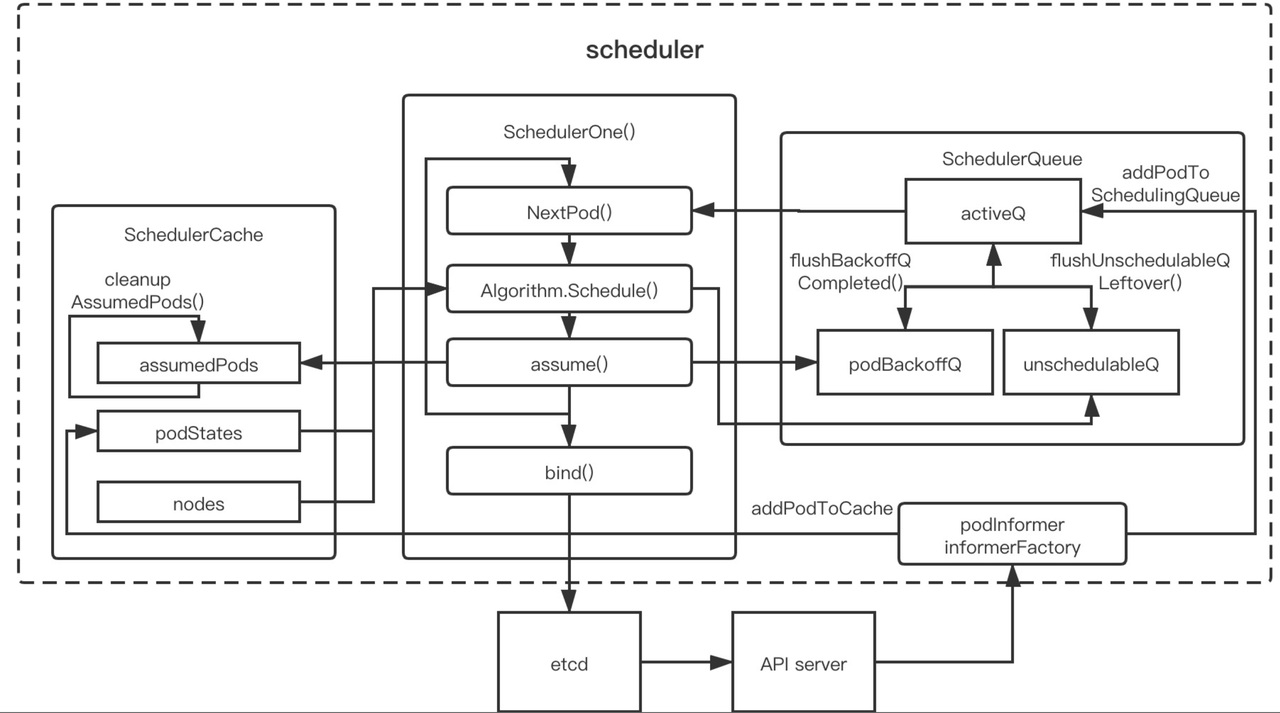
pkg/scheduler/scheduler.go:312
func (sched *Scheduler) Run(ctx context.Context) {
// 等待informers中的cache同步完成
if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) {
return
}
// 启动SchedulingQueue的goroutine,会将未调度的pod从其他两个queue放到待调度队列
sched.SchedulingQueue.Run()
// 循环执行scheduleOne实现pod调度
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
SchedulingQueue.Run() 会起两个 goroutine
- flushBackoffQCompleted 主要负责把所有 backoff 计时完毕(duration 会因为失败变长)的 pod 往 activeQ刷
- flushUnschedulableQLeftover 把所有在 unschedulableQ 的 pod 计时unschedulableQTimeInterval 完毕后送去 activeQ
scheduleOne是调度的主要实现,包含三部分:调度、调度结果处理(抢占)、绑定
pkg/scheduler/scheduler.go:434
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 获得下一个待调度的pod
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
// 获得pod的调度配置
prof, err := sched.profileForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.Error(err)
return
}
// 如果pod被删除或处于assumed、更新不进行调度
if sched.skipPodSchedule(prof, pod) {
return
}
klog.V(3).Infof("Attempting to schedule pod: %v/%v", pod.Namespace, pod.Name)
// Synchronously attempt to find a fit for the pod.
start := time.Now()
// 被plugin用来存储数据
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 进行调度
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod)
if err != nil {
// Schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
nominatedNode := ""
if fitError, ok := err.(*core.FitError); ok {
if !prof.HasPostFilterPlugins() {
klog.V(3).Infof("No PostFilter plugins are registered, so no preemption will be performed.")
} else {
// 执行PostFilter plugins,默认是抢占调度
result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses)
if status.Code() == framework.Error {
klog.Errorf("Status after running PostFilter plugins for pod %v/%v: %v", pod.Namespace, pod.Name, status)
} else {
klog.V(5).Infof("Status after running PostFilter plugins for pod %v/%v: %v", pod.Namespace, pod.Name, status)
}
if status.IsSuccess() && result != nil {
nominatedNode = result.NominatedNodeName
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(prof.Name, metrics.SinceInSeconds(start))
} else if err == core.ErrNoNodesAvailable {
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(prof.Name, metrics.SinceInSeconds(start))
} else {
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
}
sched.recordSchedulingFailure(prof, podInfo, err, v1.PodReasonUnschedulable, nominatedNode)
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// 更新schedulerCache
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
sched.recordSchedulingFailure(prof, assumedPodInfo, err, SchedulerError, "")
return
}
// 执行reserve plugins,预留资源
if sts := prof.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
// trigger un-reserve to clean up state associated with the reserved Pod
prof.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache().ForgetPod(assumedPod); forgetErr != nil {
klog.Errorf("scheduler cache ForgetPod failed: %v", forgetErr)
}
sched.recordSchedulingFailure(prof, assumedPodInfo, sts.AsError(), SchedulerError, "")
return
}
// Run "permit" plugins. 准入
runPermitStatus := prof.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if runPermitStatus.Code() != framework.Wait && !runPermitStatus.IsSuccess() {
var reason string
if runPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(prof.Name, metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
reason = SchedulerError
}
// One of the plugins returned status different than success or wait.
prof.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache().ForgetPod(assumedPod); forgetErr != nil {
klog.Errorf("scheduler cache ForgetPod failed: %v", forgetErr)
}
sched.recordSchedulingFailure(prof, assumedPodInfo, runPermitStatus.AsError(), reason, "")
return
}
// 执行bind
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues("binding").Inc()
defer metrics.SchedulerGoroutines.WithLabelValues("binding").Dec()
waitOnPermitStatus := prof.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
var reason string
if waitOnPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(prof.Name, metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
reason = SchedulerError
}
// trigger un-reserve plugins to clean up state associated with the reserved Pod
prof.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache().ForgetPod(assumedPod); forgetErr != nil {
klog.Errorf("scheduler cache ForgetPod failed: %v", forgetErr)
}
sched.recordSchedulingFailure(prof, assumedPodInfo, waitOnPermitStatus.AsError(), reason, "")
return
}
// Run "prebind" plugins.
preBindStatus := prof.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
prof.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache().ForgetPod(assumedPod); forgetErr != nil {
klog.Errorf("scheduler cache ForgetPod failed: %v", forgetErr)
}
sched.recordSchedulingFailure(prof, assumedPodInfo, preBindStatus.AsError(), SchedulerError, "")
return
}
// 执行bind extender/plugins,默认bind实现通过client更新pod
err := sched.bind(bindingCycleCtx, prof, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
metrics.PodScheduleError(prof.Name, metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
prof.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if err := sched.SchedulerCache.ForgetPod(assumedPod); err != nil {
klog.Errorf("scheduler cache ForgetPod failed: %v", err)
}
sched.recordSchedulingFailure(prof, assumedPodInfo, fmt.Errorf("Binding rejected: %v", err), SchedulerError, "")
} else {
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
if klog.V(2).Enabled() {
klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
}
metrics.PodScheduled(prof.Name, metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// Run "postbind" plugins.
prof.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
}
}()
}
pkg/scheduler/core/generic_scheduler.go:138 调度算法进行调度
func (g *genericScheduler) Schedule(ctx context.Context, prof *profile.Profile, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 检查pvc是否已经ready
if err := podPassesBasicChecks(pod, g.pvcLister); err != nil {
return result, err
}
trace.Step("Basic checks done")
// 1. 更新node snapshot(基于共享状态的调度,类似事务); cache->snapshot
if err := g.snapshot(); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
startPredicateEvalTime := time.Now()
// 2. 对node进行预选,filter plugins、extenders
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, prof, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &FitError{
Pod: pod,
NumAllNodes: g.nodeInfoSnapshot.NumNodes(),
FilteredNodesStatuses: filteredNodesStatuses,
}
}
metrics.DeprecatedSchedulingAlgorithmPredicateEvaluationSecondsDuration.Observe(metrics.SinceInSeconds(startPredicateEvalTime))
metrics.DeprecatedSchedulingDuration.WithLabelValues(metrics.PredicateEvaluation).Observe(metrics.SinceInSeconds(startPredicateEvalTime))
startPriorityEvalTime := time.Now()
// 只有一个node不需要进行优选
if len(feasibleNodes) == 1 {
metrics.DeprecatedSchedulingAlgorithmPriorityEvaluationSecondsDuration.Observe(metrics.SinceInSeconds(startPriorityEvalTime))
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(filteredNodesStatuses),
FeasibleNodes: 1,
}, nil
}
// 3. 优选,Score pluagins、extenders,结果为node名称、score的struct slice
priorityList, err := g.prioritizeNodes(ctx, prof, state, pod, feasibleNodes)
if err != nil {
return result, err
}
metrics.DeprecatedSchedulingAlgorithmPriorityEvaluationSecondsDuration.Observe(metrics.SinceInSeconds(startPriorityEvalTime))
metrics.DeprecatedSchedulingDuration.WithLabelValues(metrics.PriorityEvaluation).Observe(metrics.SinceInSeconds(startPriorityEvalTime))
// 4. 选择score最大的host,score相同时会随机更新遍历的node节点
host, err := g.selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(filteredNodesStatuses),
FeasibleNodes: len(feasibleNodes),
}, err
}
scheduler默认inTree plugins在
pkg/scheduler/alogrithmprovider/registry.go:78
func getDefaultConfig() *schedulerapi.Plugins {
return &schedulerapi.Plugins{
QueueSort: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// 按优先级排序
{Name: queuesort.Name},
},
},
PreFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// node资源是否满足pod
{Name: noderesources.FitName},
// 端口冲突检查
{Name: nodeports.Name},
// 拓扑区域检查类似az
{Name: podtopologyspread.Name},
// pod亲和性
{Name: interpodaffinity.Name},
// 卷
{Name: volumebinding.Name},
},
},
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
// 节点亲和性
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
// pod拓扑约束
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
},
},
PostFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// 抢占
{Name: defaultpreemption.Name},
},
},
PreScore: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name},
{Name: podtopologyspread.Name},
{Name: tainttoleration.Name},
},
},
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
// 镜像本地
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},
Reserve: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
PreBind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
Bind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// 默认bind,client调用Bind
{Name: defaultbinder.Name},
},
},
}
}
参考
Omega: flexible, scalable schedulers for large compute clusters(共享状态调度)