
基础
算法与数据结构
数据结构
- 数组与链表
- 栈与队列
- 优先队列
- 树
- 哈希表
- 并差集
- Trie树
- 布隆过滤器: 可以确定不存在
- LRU cache
- 图
skiplist
随机化数据结构log(n)
插入:插入时先查找到当前插入节点的前缀,随机生产新节点的level,从level到底层逐步更新前缀指针
rbtree
- 每个节点要么是黑色,要么是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。
- 每个红色结点的两个子结点一定都是黑色。
- 任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
算法
- 贪心 哈夫曼编码、最短生成树prim and cruskarl
- 递归
- 遍历
- 深度优先与广度优先搜索
- 分治法
- 动态规划
数组与链表
- 基本操作时间复杂度
| op | 数组array | 链表linked lsit |
|---|---|---|
| access | O(1) | O(n) |
| insert | O(n) | O(1) |
| delete | O(n) | O(1) |
- 常见题目
- 翻转链表
- 判断链表是否有环 (快慢指针)
栈与队列
- 栈 FILO
- 队列 FIFO
- 常见题目
- 括号匹配
- 队列实现栈(写直接入队列,读数据入另一队列剩1个即为栈顶),栈实现队列(写入数据直接压栈,读时排空一个栈,取栈顶)
优先队列(heap)
- 正常入,按优先级出
- 操作时间复杂度
- 斐波那契堆是一系列无序树的集合,每棵树是一个最小堆,满足最小堆的性质
| op | binary | fibonacci |
|---|---|---|
| find-min | Θ(1) | Θ(1) |
| delete-min | Θ(log n) | O(log n) |
| insert | O(log n) | Θ(1) |
| merge | Θ(n) | Θ(1) |
- 常见题目
- kth largest in stream
- 滑动窗口
哈希表
- 2sum
- 3sum
树与二叉树
- binary search tree 验证: 带上下界递归遍历
- 最小公共祖先
递归与分治
- Pow(x, n)
- 一组数的大多数
贪心算法
问题能够分解成子问题,子问题的最优解能递推到最终问题的最优解
广度优先搜索
利用队列
深度优先搜索
利用栈
位运算
- x & 1 == 0 OR == 1 判断奇偶
- x = x & (x-1) 清零最低位的1
- x & -x 得到最低位的1
操作系统
linux内核调度算法
- O(n) 0.1x-2.4
说明: 固定时间片counter(15ms),从rq队列中选择优先级最高的,当无就绪进程时,counter重新赋值 counter=counter/2 + priority,对等待IO的进程且时间片未用完的有一定公平性
缺点:O(n)效率低,需要重复计算时间片,当进程用完时间片必须等待再次赋值,才可以调度
- O(1) 2.5-2.6
说明:O(1)将进程分为0-139个等级,0-99为实时进程优先级,100-139为普通进程优先级,数值越低优先级越高;调度器为每个CPU维护两个数组,active与expire,数组存储优先级队列,从active选择最小数第一个进程,时间片用完后将进程放入expire数组,当active为空时,active与expire互换。支持抢占
缺点:在很多情况下会失效,有一些著名的程序总能让该调度器性能下降,导致交互式进程反应缓慢
- CFS 2.6
说明:CFS使用“虚拟运行时”表示某个任务的时间量。任务的虚拟运行时越小,意味着任务被允许访问服务器的时间越短,其对处理器的需求越高,
CFS没有将任务维护在链表式的运行队列中,它抛弃了active/expire数组,而是对每个CPU维护一个以时间为顺序的红黑树。该树方法能够良好运行的原因在于: - 红黑树可以始终保持平衡,这意味着树上没有路径比任何其他路径长两倍以上。 - 由于红黑树是二叉树,查找操作的时间复杂度为O(log n)。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。 - 对于大多数操作(插入、删除、查找等),红黑树的执行时间为O(log n),而以前的调度程序通过具有固定优先级的优先级数组使用 O(1)。O(log n)性能可接受范围。 - 红黑树可通过内部存储实现,即不需要使用外部分配即可对数据结构进行维护。
- tick中断 在CFS中,tick中断首先更新调度信息。然后调整当前进程在红黑树中的位置。调整完成后如果发现当前进程不再是最左边的叶子,就标记need_resched标志,中断返回时就会调用scheduler()完成进程切换。否则当前进程继续占用CPU。从这里可以看到 CFS抛弃了传统的时间片概念。Tick中断只需更新红黑树,以前的所有调度器都在tick中断中递减时间片,当时间片或者配额被用完时才触发优先级调整并重新调度。
- 红黑树键值计算 理解CFS的关键就是了解红黑树键值的计算方法。该键值由三个因子计算而得:一是进程已经占用的CPU时间;二是当前进程的nice值(-20-+19);三是当前的cpu负载。进程已经占用的CPU时间对键值的影响最大,其实很大程度上我们在理解CFS时可以简单地认为键值就等于进程已占用的 CPU时间。因此该值越大,键值越大,从而使得当前进程向红黑树的右侧移动。另外CFS规定,nice值为1的进程比nice值为0的进程多获得10%的 CPU时间。在计算键值时也考虑到这个因素,因此nice值越大,键值也越大。 CFS为每个进程都维护两个重要变量:fair_clock和wait_runtime。这里我们将为每个进程维护的变量称为进程级变量,为每个CPU维护的称作CPU级变量,为每个runqueue维护的称为runqueue级变量。进程插入红黑树的键值即为fair_clock – wait_runtime。其中fair_clock从其字面含义上讲就是一个进程应获得的CPU时间,即等于进程已占用的CPU时间除以当前 runqueue中的进程总数;wait_runtime是进程的等待时间。它们的差值代表了一个进程的公平程度。该值越大,代表当前进程相对于其它进程越不公平。对于交互式任务,wait_runtime长时间得不到更新,因此它能拥有更高的红黑树键值,更靠近红黑树的左边。从而得到快速响应。 红黑树是平衡树,调度器每次总最左边读出一个叶子节点,该读取操作的时间复杂度是O(LgN)。
进程状态
- TASK_RUNNING 运行状态
- TASK_INTERRUPTIBLE 可中断睡眠状态,针对等待某件事或其他资源的睡眠进程设置的,在内核发送信号给该进程表明事件发生时,进程状态转变为TASK_RUNNING,只要调度器选中该进程即可恢复执行
- TASK_UNINTERRUPTIBLE由于内核指示而停用的睡眠进程,他们不能由外部信号唤醒,只能由内核亲自唤醒
- TASK_STOPPED 停止
- TASK_ZOMBIE 僵尸状态
top命令中的loadavg是5,10,15分钟的TASK_RUNNING+TASK_UNINTERRUPTINLE进程的平均数,数值为核数时负载满
内存管理
文件系统
设备管理
缓存与锁
网络
TCP
- SYN: 解决网络包乱序
- ACK: 解决丢包问题
- 滑动窗口: 流控
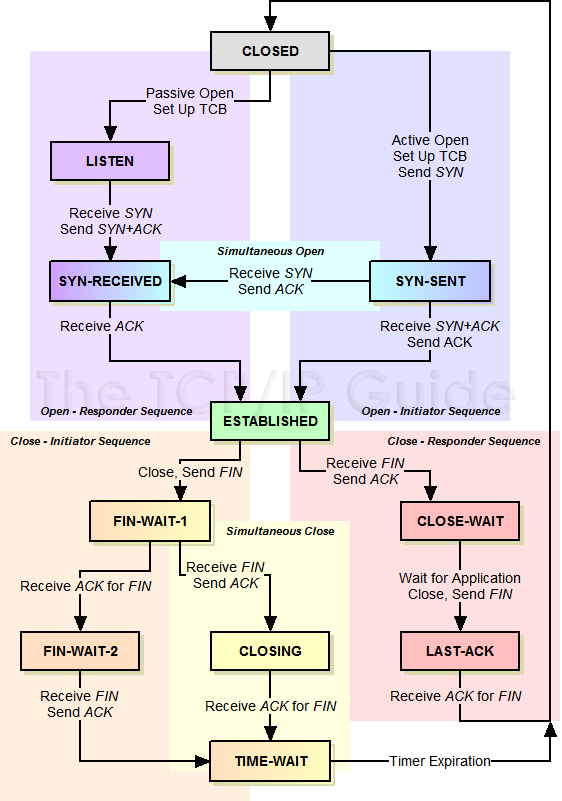
三次握手与4次挥手
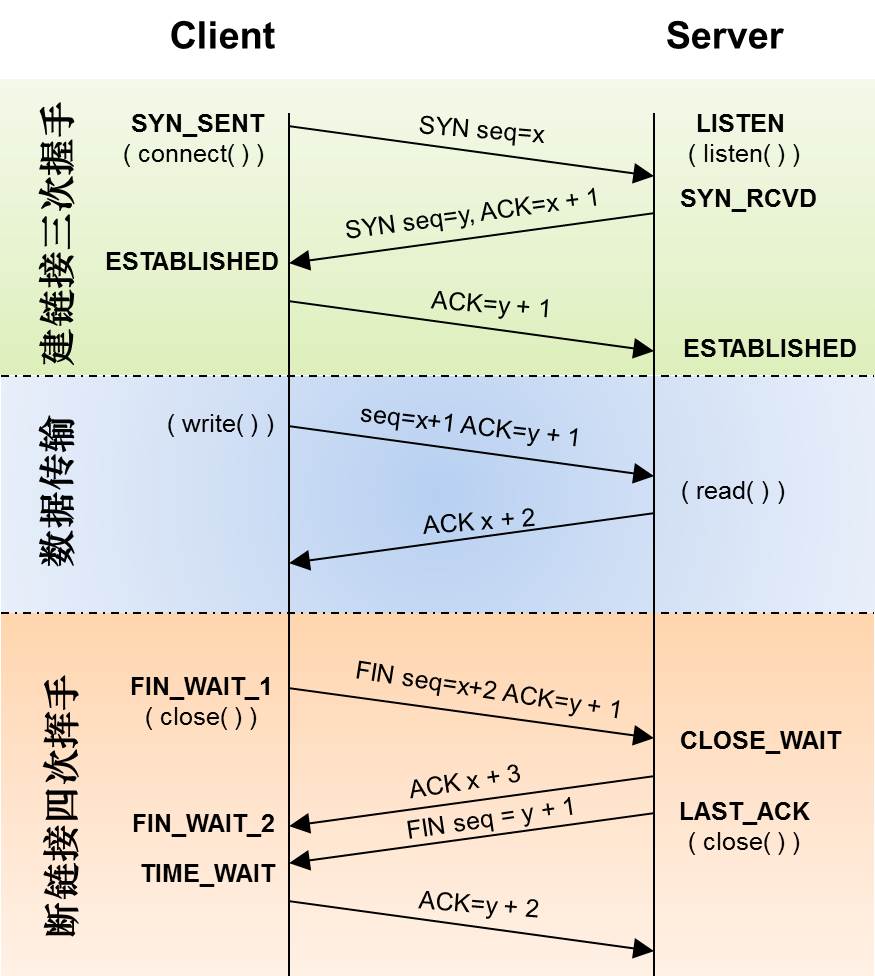
- 对于建链接的3次握手,主要是要初始化Sequence Number 的初始值。通信的双方要互相通知对方自己的初始化的Sequence Number,作为以后的数据通信的序号,以保证应用层接收到的数据不会因为网络上的传输的问题而乱序
- 对于4次挥手,其实你仔细看是2次,因为TCP是全双工的,所以,发送方和接收方都需要Fin和Ack。如果两边同时断连接,那就会就进入到CLOSING状态,然后到达TIME_WAIT状态。
TIME_WAIT与CLOSE_WAIT
- CLOSE_WAIT: 被动收到FIN后进入CLOSE_WAIT,等待应用处理
- TIME_WAIT: 主动发送FIN后进入TIME_WAIT,等待2MSL进入CLOSE状态。主要有两个原因:1)TIME_WAIT确保有足够的时间让对端收到了ACK,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)有足够的时间让这个连接不会跟后面的连接混在一起。如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源,主要避免方法时服务端不要主动关闭。
HTTPS
- 安全
- 身份验证
- 完整性验证
既有对称加密又有非对称加密
非对称加密:a. TLS握手阶段对对称加密密钥沟通时加密 b. 身份验证时使用 区别:a的私钥在服务器端 b的私钥在CA 对称加密:对传输数据进行加密,密钥在TLS握手时确定
证书:由CA颁发,包含证书信息、hash算法、签名 签名:验证,根据公钥解密,对CA证书信息中除签名外的信息进行hash算对比,一样则身份验证通过
设计模式
创建型模式
- 简单工厂模式(Simple Factory)
- 解决问题:
- 优点:
- 缺点:
工厂方法模式(Factory Method)
抽象工厂模式(Abstract Factory)
单例模式(Singleton)
public class Singleton{ private Singleton(){} private static Singleton instance = null; public Singleton getInstance(){ if(instance == null){ instance = new Singleton(); } return instance; } }
结构型模式
- 适配器模式(Adapter)
- 组合模式(Composite)
- 装饰模式(Decorator)
- 代理模式(Proxy)
行为型模式
- 迭代器模式(Iterator)
- 观察者模式(Observer)
编程语言
java
集合
接口
为了规范容器的行为,统一设计,JCF定义了14种容器接口(collection interfaces),它们的关系如下图所示:
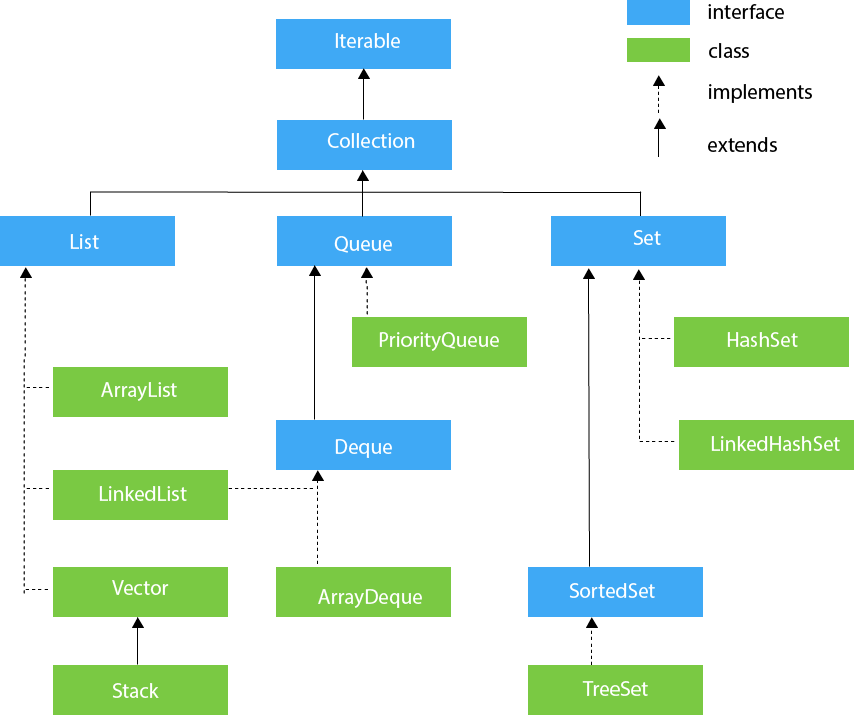 *Map*接口没有继承自*Collection*接口,因为*Map*表示的是关联式容器而不是集合。但Java为我们提供了从*Map*转换到*Collection*的方法,可以方便的将*Map*切换到集合视图。
上图中提供了*Queue*接口,却没有*Stack*,这是因为*Stack*的功能已被JDK 1.6引入的*Deque*取代。
*Map*接口没有继承自*Collection*接口,因为*Map*表示的是关联式容器而不是集合。但Java为我们提供了从*Map*转换到*Collection*的方法,可以方便的将*Map*切换到集合视图。
上图中提供了*Queue*接口,却没有*Stack*,这是因为*Stack*的功能已被JDK 1.6引入的*Deque*取代。
实现
上述接口的通用实现见下表:
| Implementations | ||||||
|---|---|---|---|---|---|---|
| Hash Table | Resizable Array | Balanced Tree | Linked List | Hash Table + Linked List | ||
| Interfaces | Set | HashSet | TreeSet | LinkedHashSet | ||
| List | ArrayList | LinkedList | ||||
| Deque | ArrayDeque | LinkedList | ||||
| Map | HashMap | TreeMap | LinkedHashMap | |||
迭代器(Iterator)
//visit a list with iterator
ArrayList<String> list = new ArrayList<String>();
list.add(new String("Monday"));
list.add(new String("Tuesday"));
list.add(new String("Wensday"));
Iterator<String> it = list.iterator();//得到迭代器
while(it.hasNext()){
String weekday = it.next();//访问元素
System.out.println(weekday.toUpperCase());
}
JDK 1.5 引入了增强的for循环,简化了迭代容器时的写法。
//使用增强for迭代
ArrayList<String> list = new ArrayList<String>();
list.add(new String("Monday"));
list.add(new String("Tuesday"));
list.add(new String("Wensday"));
for(String weekday : list){//enhanced for statement
System.out.println(weekday.toUpperCase());
}
ConcurrentHashMap与LinkedHashMap
ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
JDK 1.8 的实现也在链表过长8时会转换为红黑树。
LinkedHashMap:LRU,链表+hashmap
并发
线程基础
- 继承Thread实现run方法,不推荐,耦合度高
- 实现Runable接口
public interface Runable{
void run();
}
1. Runable r = ()->{ code }
2. Thread t = new Thread(r)
3. t.start()
执行器Executors:包含许多静态工厂方法来构建线程池
CachedThreadPool:一个任务创建一个线程; FixedThreadPool:所有任务只能使用固定大小的线程; SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool 1 ) 调用 Executors 类中静态的方法 newCachedThreadPool 或 newFixedThreadPool。 2 ) 调用 submit 提交 Runnable 或 Callable 对象。 3 ) 如果想要取消一个任务, 或如果提交 Callable 对象, 那就要保存好返回的 Future 象。 4 ) 当不再提交任何任务时,调用 shutdown。
Synchronized 和 ReenTrantLock 的对比
- 两者都是可重入锁
- synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API
- ReenTrantLock 比 synchronized 增加了一些高级功能:①等待可中断;②可实现公平锁;③可实现选择性通知
JUC
java.util.concurrent(J.U.C)大大提高了并发性能,AQS(AbstractQueuedSynchronizer) 被认为是 J.U.C 的核心。
JVM
内存模型
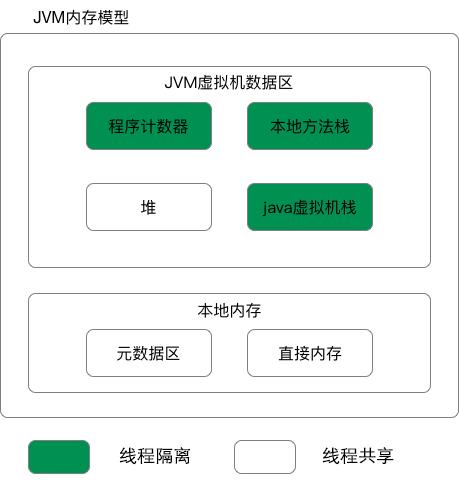
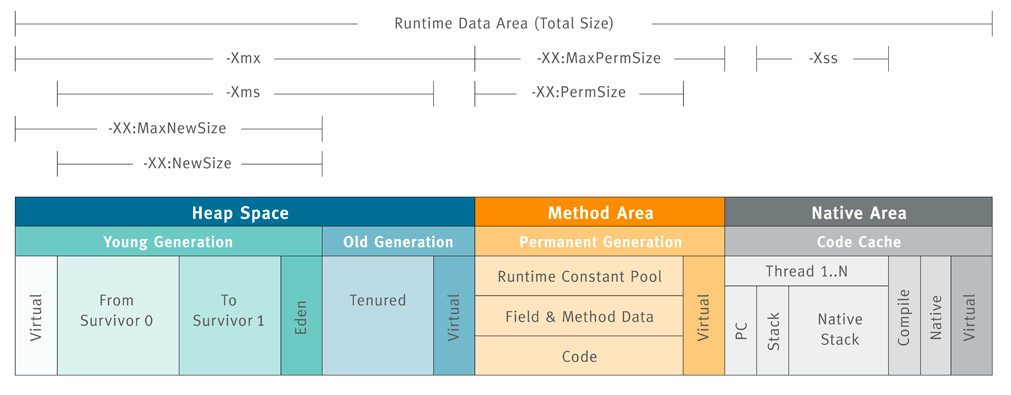
- 程序计数器(PC)是唯一不会产生OutOfMemoryError的区域
- Java 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息,Xss
- 本地方法栈: 本地方法栈与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务, 本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的
- 堆: 所有对象都在这里分配内存,是垃圾收集的主要区域(”GC 堆”)Xms Xmx
- 方法区:用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
- 直接内存:堆外内存
引用
强引用 即使OutOfMemory也不会被回收
软引用 SoftReference 内存不足时会被回收
弱引用 WeakReference GC时会被回收
虚引用 PhantomReference 不影响生命周期,必须和引用队列使用
垃圾回收算法
GcRoots可达性
思想:标记-清楚算法(碎步化、效率低)/复制算法(eden/survivor 8:1)/标记-整理算法(需要移动大量对象,处理效率比较低)
新生代:复制算法 老年代:标记-清除算法/标记-整理算法
Java 虚拟机会监视,如果所有对象都很稳定,垃圾回收的效率降低的话,就切换到”标记-清扫”方式。同样,Java 虚拟机会跟踪”标记-清扫”的效果,如果堆空间出现很多碎片,就会切换回”停止-复制”方式。这就是”自适应”的由来,你可以给它个啰嗦的称呼:”自适应的、分代的、停止-复制、标记-清扫”式的垃圾回收器
7种垃圾收集器
CMS 标记 - 清除算法
初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。 并发清除:不需要停顿。G1
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
初始标记
并发标记
最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
特点:
空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
full gc与minor gc触发条件
大多数情况下,对象在新生代 Eden 上分配,当 Eden 空间不够时,发起 Minor GC;
full gc
- 调用 System.gc()
- 老年代空间不足
- 空间分配担保失败
哪些对象可以作为GC Roots
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(即一般说的Native方法)引用的对象。
新特性
java8
Lambda 接口默认方法与静态方法 方法引用包含构造方法引用
IO&NIO&AIO
python
生成器与迭代器
装饰器
go
软件技术
Spring(简单了解)
AOP&IOC的实现
- AOP 基于代理模式
- IOC容器:通过引入IOC容器,利用依赖关系注入的方式,实现对象之间的解耦
IOC容器的工作模式看做是工厂模式的升华,可以把IOC容器看作是一个工厂,这个工厂里要生产的对象都在配置文件中给出定义,然后利用编程语言的的反射编程,根据配置文件中给出的类名生成相应的对象。从实现来看,IOC是把以前在工厂方法里写死的对象生成代码,改变为由配置文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性。
动态代理实现
Zookeeper
角色
- leader:处理客户端的读写请求,及集群内部各服务的调度。只有 leader 能够处理写请求
- follower:处理客户端的读请求,将写请求转发给 leader,参与 leader 选举投票
- observer:处理客户端的读请求,将写请求转发给leader,不参与选举
ZAB
ZAB协议包括两种基本的模式:崩溃恢复和消息广播。当整个 Zookeeper 集群刚刚启动或者Leader服务器宕机、重启或者网络故障导致不存在过半的服务器与 Leader 服务器保持正常通信时,所有服务器进入崩溃恢复模式,首先选举产生新的 Leader 服务器,然后集群中 Follower 服务器开始与新的 Leader 服务器进行数据同步。当集群中超过半数机器与该 Leader 服务器完成数据同步之后,退出恢复模式进入消息广播模式,Leader 服务器开始接收客户端的事务请求生成事物提案来进行事务请求处理。
选举算法和流程
FastLeaderElection(默认提供的选举算法) 目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为leader,服务器1,2成为follower。 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为follower。 服务器5启动,后面的逻辑同服务器4成为follower。
KafKa
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance
Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中
topic/consumer group/partition/offset
Kafka写入流程
producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
producer 将消息发送给该 leader
leader 将消息写入本地 log
followers 从 leader pull 消息,写入本地 log 后 向 leader 发送 ACK
leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
数据存储
Kafka中消息是以topic进行分类的,生产者通过topic向Kafka broker发送消息,消费者通过topic读取数据。然而topic在物理层面又能以partition为分组,一个topic可以分成若干个partition。partition还可以细分为segment,一个partition物理上由多个segment组成,segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为segment索引文件和数据文件。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。
特点
- 以时间复杂度为O(1)的方式提供消息持久化能力
- 高吞吐率
- 支持Kafka Server间的消息分区,及分布式消费
- 同时支持离线数据处理和实时数据处理
- Scale out:支持在线水平扩展
高性能
- 利用Partition实现并行处理,可以把一个Partition当作一个非常长的数组,可通过这个“数组”的索引(offset)去访问其数据
ISR实现可用性与数据一致性的动态平衡,Leader可以按顺序接收大量消息,最新的一条消息的Offset被记为High Wartermark。而只有被ISR中所有Follower都复制过去的消息才会被Commit,Consumer只能消费被Commit的消息commit offset;由于Follower的复制是严格按顺序的,所以被Commit的消息之前的消息肯定也已经被Commit过
1. 由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性。 2. ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。 3. ISR可动态调整,极限情况下,可以只包含Leader,极大提高了可容忍的宕机的Follower的数量。与Majority Quorum方案相比,容忍相同个数的节点失败,所要求的总节点数少了近一半。顺序写磁盘,Kafka删除Segment的方式,是直接删除Segment对应的整个log文件和整个index文件
充分利用Page Cache
支持多Disk Drive
零拷贝sendfile,4次拷贝
批处理
数据压缩降低网络负载
高效的序列化方式
ElasticSearch
Lucene中最重要的就是它的几种数据结构,这决定了数据是如何被检索的,本文再简单描述一下几种数据结构:
- FST(有限状态转移):保存term字典,可以在FST上实现单Term、Term范围、Term前缀和通配符查询等。
- 倒排链:保存了每个term对应的docId的列表,采用skipList的结构保存,用于快速跳跃。
- BKD-Tree:BKD-Tree是一种保存多维空间点的数据结构,用于数值类型(包括空间点)的快速查找。
- DocValues:基于docId的列式存储,由于列式存储的特点,可以有效提升排序聚合的性能。
Lucene数据类型
Lucene中包含了四种基本数据类型,分别是:
- Index:索引,由很多的Document组成。
- Document:由很多的Field组成,是Index和Search的最小单位。
- Field:由很多的Term组成,包括Field Name和Field Value。
- Term:由很多的字节组成。一般将Text类型的Field Value分词之后的每个最小单元叫做Term。
在lucene中,读写路径是分离的。写入的时候创建一个IndexWriter,而读的时候会创建一个IndexSearcher
写入流程
- 根据routing规则获得primary shard
- 到达primary shard写lucene创建好索引,写translog,flush到磁盘
- 写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统
- 可靠性:由于Lucene的设计中不考虑可靠性,在Elasticsearch中通过Replica和TransLog两套机制保证数据的可靠性。
- 一致性:Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但是Add完成后仍然有可能立即发生Flush,导致Segment可读。这样就没法保证Primary和所有其他Replica可以同一时间Flush,就会出现查询不稳定的情况,这里只能实现最终一致性。
- 原子性:Add和Delete都是直接调用Lucene的接口,是原子的。当部分更新时,使用Version和锁保证更新是原子的。
- 隔离性:仍然采用Version和局部锁来保证更新的是特定版本的数据。
- 实时性:使用定期Refresh Segment到内存,并且Reopen Segment方式保证搜索可以在较短时间(比如1秒)内被搜索到。通过将未刷新到磁盘数据记入TransLog,保证对未提交数据可以通过ID实时访问到。
- 性能:性能是一个系统性工程,所有环节都要考虑对性能的影响,在Elasticsearch中,在很多地方的设计都考虑到了性能,一是不需要所有Replica都返回后才能返回给用户,只需要返回特定数目的就行;二是生成的Segment现在内存中提供服务,等一段时间后才刷新到磁盘,Segment在内存这段时间的可靠性由TransLog保证;三是TransLog可以配置为周期性的Flush,但这个会给可靠性带来伤害;四是每个线程持有一个Segment,多线程时相互不影响,相互独立,性能更好;五是系统的写入流程对版本依赖较重,读取频率较高,因此采用了versionMap,减少热点数据的多次磁盘IO开销。Lucene中针对性能做了大量的优化。后面我们也会有文章专门介绍Lucene中的优化思路。
分片一致性
主备模型(一主多副本): PacificA
写:
- routing: 根据document ID 选择写目的shard, 请求转发到该shard 主分片上
- primary shard负责将写请求同步(并发)到所有replica shards, es不要求所有副本都写成功, 由primary维护了in-sync-copies
- 当in-sync-copies都写成功,返回客户写成功
- 当前分片失败,请求给到其他分片
失败处理:
- primary写入失败, master会在1min后从replica中选择primary, 由新的主完成写入请求
- replica写入失败, 在in-sync-copies的replica写入失败后,primary向master报告问题,将replica移除in-sync-copies, 移除成功后, primary返回写成功; 同时master会选择其他节点重建replica shard
- 旧的primary同步replica会被拒绝, primary从master学习新primary将请求转发
- 没有副本时, 只写primary, master不会将其他陈旧的shard设置为主
读:
- 读请求来时, 当前节点负责forward请求到分片所在节点, 汇聚结果并返回给用户
- 多副本加快读
Elasticsearch分布式一致性原理剖析(一)-节点篇
Elasticsearch分布式一致性原理剖析(二)-Meta篇
Elasticsearch分布式一致性原理剖析(三)-Data篇
如何分配分片
- 负载均衡 : SameShardAllocationDecider ShardsLimitAllocationDecider
- 并发数量规则 ConcurrentRebalanceAllocationDecider
- 条件限制 FilterAllocationDecider
怎么使用Zookeeper实现ES的上述功能
节点发现:每个节点的配置文件中配置一下Zookeeper服务器的地址,节点启动后到Zookeeper中某个目录中注册一个临时的znode。当前集群的master监听这个目录的子节点增减的事件,当发现有新节点时,将新节点加入集群。
master选举:当一个master-eligible node启动时,都尝试到固定位置注册一个名为master的临时znode,如果注册成功,即成为master,如果注册失败则监听这个znode的变化。当master出现故障时,由于是临时znode,会自动删除,这时集群中其他的master-eligible node就会尝试再次注册。使用Zookeeper后其实是把选master变成了抢master。
错误检测:由于节点的znode和master的znode都是临时znode,如果节点故障,会与Zookeeper断开session,znode自动删除。集群的master只需要监听znode变更事件即可,如果master故障,其他的候选master则会监听到master znode被删除的事件,尝试成为新的master。
集群扩缩容:扩缩容将不再需要考虑minimum_master_nodes配置的问题,会变得更容易。
与使用raft相比
raft算法是近几年很火的一个分布式一致性算法,其实现相比paxos简单,在各种分布式系统中也得到了应用。这里不再描述其算法的细节,我们单从master选举算法角度,比较一下raft与ES目前选举算法的异同点:
相同点
多数派原则:必须得到超过半数的选票才能成为master。
选出的leader一定拥有最新已提交数据:在raft中,数据更新的节点不会给数据旧的节点投选票,而当选需要多数派的选票,则当选人一定有最新已提交数据。在es中,version大的节点排序优先级高,同样用于保证这一点。
不同点
正确性论证:raft是一个被论证过正确性的算法,而ES的算法是一个没有经过论证的算法,只能在实践中发现问题,做bug fix,这是我认为最大的不同。
是否有选举周期term:raft引入了选举周期的概念,每轮选举term加1,保证了在同一个term下每个参与人只能投1票。ES在选举时没有term的概念,不能保证每轮每个节点只投一票。
选举的倾向性:raft中只要一个节点拥有最新的已提交的数据,则有机会选举成为master。在ES中,version相同时会按照NodeId排序,总是NodeId小的人优先级高。
Redis
数据类型
- String字符串:字符串类型是 Redis 最基础的数据结构,首先键都是字符串类型,而且 其他几种数据结构都是在字符串类型基础上构建的,我们常使用的 set key value 命令就是字符串。常用在缓存、计数、共享Session、限速等。
- Hash哈希:在Redis中,哈希类型是指键值本身又是一个键值对结构,哈希可以用来存放用户信息,比如实现购物车。
- List列表(双向链表):列表(list)类型是用来存储多个有序的字符串。可以做简单的消息队列的功能。
- Set集合:集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一 样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。利用 Set 的交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
- Sorted Set有序集合(跳表实现):Sorted Set 多了一个权重参数 Score,集合中的元素能够按 Score 进行排列。可以做排行榜应用,取 TOP N 操作。
zset跳表的数据结构
数据过期策略
- 定期删除策略:Redis 启用一个定时器定时监视所有的 key,判断key是否过期,过期的话就删除。这种策略可以保证过期的 key 最终都会被删除,但是也存在严重的缺点:每次都遍历内存中所有的数据,非常消耗 CPU 资源,并且当 key 已过期,但是定时器还处于未唤起状态,这段时间内 key 仍然可以用。
- 惰性删除策略:在获取 key 时,先判断 key 是否过期,如果过期则删除。这种方式存在一个缺点:如果这个 key 一直未被使用,那么它一直在内存中,其实它已经过期了,会浪费大量的空间。
这两种策略天然的互补,结合起来之后,定时删除策略就发生了一些改变,不在是每次扫描全部的 key 了,而是随机抽取一部分 key 进行检查,这样就降低了对 CPU 资源的损耗,惰性删除策略互补了为检查到的key,基本上满足了所有要求。但是有时候就是那么的巧,既没有被定时器抽取到,又没有被使用,这些数据又如何从内存中消失?没关系,还有- 内存淘汰机制,当内存不够用时,内存淘汰机制就会上场。淘汰策略分为:
- 当内存不足以容纳新写入数据时,新写入操作会报错。(Redis 默认策略)
- 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。(LRU推荐使用)
- 当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。
- 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。
- 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。
- 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。
LRU过期策略的实现
传统的LRU是使用栈的形式,每次都将最新使用的移入栈顶,但是用栈的形式会导致执行select *的时候大量非热点数据占领头部数据,所以需要改进。Redis每次按key获取一个值的时候,都会更新value中的lru字段为当前秒级别的时间戳。Redis初始的实现算法很简单,随机从dict中取出五个key,淘汰一个lru字段值最小的。在3.0的时候,又改进了一版算法,首先第一次随机选取的key都会放入一个pool中(pool的大小为16),pool中的key是按lru大小顺序排列的。接下来每次随机选取的keylru值必须小于pool中最小的lru才会继续放入,直到将pool放满。放满之后,每次如果有新的key需要放入,需要将pool中lru最大的一个key取出。淘汰的时候,直接从pool中选取一个lru最小的值然后将其淘汰。
持久化aof/rdb
aof: 把所有的对Redis的服务器进行修改的命令都存到一个文件里,命令的集合。 使用AOF做持久化,每一个写命令都通过write函数追加到appendonly.aof中。aof的默认策略是每秒钟fsync一次,在这种配置下,就算发生故障停机,也最多丢失一秒钟的数据。 缺点是对于相同的数据集来说,AOF的文件体积通常要大于RDB文件的体积。根据所使用的fsync策略,AOF的速度可能会慢于RDB。 Redis默认是快照RDB的持久化方式。对于主从同步来说,主从刚刚连接的时候,进行全量同步(RDB);全同步结束后,进行增量同步(AOF)
rdb: 快照形式是直接把内存中的数据保存到一个dump的文件中,定时保存,保存策略。 当Redis需要做持久化时,Redis会fork一个子进程,子进程将数据写到磁盘上一个临时RDB文件中。当子进程完成写临时文件后,将原来的RDB替换掉
缓存穿透与缓存雪崩
- 缓存雪崩
- 使用 Redis 高可用架构:使用 Redis 集群来保证 Redis 服务不会挂掉
- 缓存时间不一致,给缓存的失效时间,加上一个随机值,避免集体失效
- 限流降级策略:有一定的备案,比如个性推荐服务不可用了,换成热点数据推荐服务
- 缓存穿透
- 接口做校验
- 存null值(缓存击穿加锁)
- 布隆过滤器拦截: 将所有可能的查询key 先映射到布隆过滤器中,查询时先判断key是否存在布隆过滤器中,存在才继续向下执行,如果不存在,则直接返回。布隆过滤器将值进行多次哈希bit存储,布隆过滤器说某个元素在,可能会被误判。布隆过滤器说某个元素不在,那么一定不在。
etcd
支持的操作
- put(key, vlaue)/delete(key)
- get(key)/get(keyFrom, keyEnd)
- watch(key/keyPrefix)
- transactions(if/then/else ops).commit
- leases 租期
版本机制
- term 全局递增,raft leader任期
- revision 全局递增,任何数据变更后会自增
KeyValue
create_revision 创建时全局revision值 mod_revision 修改时全局revision值 version keyvalue的修改版本mvcc
一个数据有多个版本 通过定期compaction清理数据
典型应用场景
- 元数据存储 (k8s api资源对象)
- 服务发现
- 选主
- 分布式系统并发控制
MySQL
最左前缀匹配
- 如果你创建一个联合索引,那这个索引的任何前缀都会用于查询, (col1, col2, col3)这个联合索引的所有前缀就是(col1), (col1, col2), (col1, col2, col3),包含这些列的查询都会启用索引查询.
其他所有不在最左前缀里的列都不会启用索引,即使包含了联合索引里的部分列也不行. 即上述中的(col2), (col3), (col2, col3) 都不会启用索引去查询.注意, (col1, col3)会启用(col1)的索引查询
联合索引最多只能包含16列
blob和text也能创建索引, 但是必须指定前面多少位
联合索引的替代方案:可以额外创建一列,其列值由联合索引包含的所有列值所生成的hash值来构成
非聚集索引与聚集索引(innodb)
B+树叶子节点可能存储的是整行数据,也有可能是主键的值。B+树的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引。而索引B+ Tree的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引
事物隔离级别
- read uncommited 脏读
- read commited 不可重复读
- read repeated + mvcc 幻读
- serialize
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据 不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。 幻读:A事务读取了B事务已经提交的新增数据。注意和不可重复读的区别,这里是新增,不可重复读是更改(或删除)。select某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommited | 是 | 是 | 是 |
| read commited | 否 | 是 | 是 |
| read repeated | 否 | 否 | 是 |
| serialize | 否 | 否 | 否 |
innodb表锁与行锁
- 共享锁(S):用法lock in share mode,又称读锁,允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
- 排他锁(X):用法for update,又称写锁,允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。在没有索引的情况下,InnoDB只能使用表锁。
explain如何解析SQL
SQL的执行顺序:from—where–group by—having—select—order by
MVCC多版本并发控制
- MVCC多版本并发控制是MySQL中基于乐观锁理论实现隔离级别的方式,用于读已提交和可重复读取隔离级别的实现。在MySQL中,会在表中每一条数据后面添加两个字段:最近修改该行数据的事务ID,指向该行(undolog表中)回滚段的指针。Read View判断行的可见性,创建一个新事务时,copy一份当前系统中的活跃事务列表。意思是,当前不应该被本事务看到的其他事务id列表。
binlog & redolog & undolog
- undoLog 是我们常说的回滚日志文件 主要用于事务中执行失败,进行回滚,以及MVCC中对于数据历史版本的查看。由引擎层的InnoDB引擎实现,是逻辑日志,记录数据修改被修改前的值,比如”把id=‘B’ 修改为id = ‘B2’ ,那么undo日志就会用来存放id =‘B’的记录”。当一条数据需要更新前,会先把修改前的记录存储在undolog中,如果这个修改出现异常,,则会使用undo日志来实现回滚操作,保证事务的一致性。当事务提交之后,undo log并不能立马被删除,而是会被放到待清理链表中,待判断没有事物用到该版本的信息时才可以清理相应undolog。它保存了事务发生之前的数据的一个版本,用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
- redoLog 是重做日志文件是记录数据修改之后的值,用于持久化到磁盘中。redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。由引擎层的InnoDB引擎实现,是物理日志,记录的是物理数据页修改的信息,比如“某个数据页上内容发生了哪些改动”。当一条数据需要更新时,InnoDB会先将数据更新,然后记录redoLog 在内存中,然后找个时间将redoLog的操作执行到磁盘上的文件上。不管是否提交成功我都记录,你要是回滚了,那我连回滚的修改也记录。它确保了事务的持久性。MySQL为了保证ACID中的一致性和持久性,使用了WAL(Write-Ahead Logging,先写日志再写磁盘)。Redo log就是一种WAL的应用。当数据库忽然掉电,再重新启动时,MySQL可以通过Redo log还原数据。也就是说,每次事务提交时,不用同步刷新磁盘数据文件,只需要同步刷新Redo log就足够了。
- binlog由Mysql的Server层实现,是逻辑日志,记录的是sql语句的原始逻辑,比如”把id=‘B’ 修改为id = ‘B2’。binlog会写入指定大小的物理文件中,是追加写入的,当前文件写满则会创建新的文件写入。 产生:事务提交的时候,一次性将事务中的sql语句,按照一定的格式记录到binlog中。用于复制和恢复在主从复制中,从库利用主库上的binlog进行重播(执行日志中记录的修改逻辑),实现主从同步。业务数据不一致或者错了,用binlog恢复。
分布式架构
CAP
- consistency一致性
- avaliable可用性
- partition分区容忍性
P是一定存在的,所以一般选择为AP,CP
2PC
参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作
- 提交请求阶段
提交执行阶段
协调者 参与者 QUERY TO COMMIT --------------------------------> VOTE YES/NO prepare*/abort* <------------------------------- commit*/abort* COMMIT/ROLLBACK --------------------------------> ACKNOWLEDGMENT commit*/abort* <-------------------------------- end
缺点:二阶段提交算法的最大缺点就在于它的执行过程中间,节点都处于阻塞状态。即节点之间在等待对方的响应消息时,它将什么也做不了。特别是,当一个节点在已经占有了某项资源的情况下,为了等待其他节点的响应消息而陷入阻塞状态时,当第三个节点尝试访问该节点占有的资源时,这个节点也将连带陷入阻塞状态。
分布式一致性模式
弱一致性 VOIP
读可能会拿到最新的写
最终一致性 DNS
读最终会拿到最新的写
强一致性 关系型数据库(CP zookeeper)
读总能拿到最新的写
基础理论及模式
paxos
- proposers 提议
- acceptor 表决
- learner 学习结果
P1a:当且仅当acceptor没有回应过编号大于n的prepare请求时,acceptor接受(accept)编号为n的提案。
- prepare阶段:
- proposer选择一个提案编号n并将prepare请求发送给acceptors中的一个多数派;
- acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息(回复消息表示接受accept),则acceptor将自己上次接受的提案回复给proposer,并承诺不再回复小于n的提案;
- 批准阶段:
- 当一个proposer收到了多数acceptors对prepare的回复后,就进入批准阶段。它要向回复prepare请求的acceptors发送accept请求,包括编号n和根据P2c决定的value(如果根据P2c没有已经接受的value,那么它可以自由决定value)。
- 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept请求后即批准这个请求。
raft(paxos变种)
- leader
- follower
- candidate
领袖会借由固定时间发送消息,也就是“心跳(heartbeat,让追随者知道集群的领袖还在运作。而每个追随者都会设计timeout机制,当超过一定时间没有收到心跳(通常是150 ms或300 ms),集群就会进入选举状态。
唯一的leader接受外部请求
随机的timeout解决冲突
算法主要包括
- leader选举(term 选举周期)
- 日志复制
Pacifica
微软2008年提出的日志复制协议,与PaxOS和Raft不同,PacificA并不提供Leader选举,因此需要结合PaxOS或Raft,分布式消息队列Kafka的ISR算法类似于PacificA。小米开源的KV系统Pegasus基于PacificA实现。
Cloud Native
K8S
borg/omega/k8s差异
borg 有master、api、一致性存储、borglet等组成;将调度、控制逻辑都做到master中,导致master很复杂,一致性算法为paxos实现。
omega:Omega存储了基于Paxos、围绕transaction的集群的状态,能够被集群的控制面板(比如调度器)接触到,使用了优化的进程控制来解决偶尔发生的冲突。这种分离允许Borgmaster的功能被区分成几个并列的组建,而不是把所有变化都放到一个单独的、巨石型的master里。
API对象:API对象是Kubernetes集群中的管理操作单元
API对象3类属性
- 元数据metadata:namespace、name、uid和label
- 规范spec:描述了用户期望Kubernetes集群中的分布式系统达到的理想状
- 状态status:描述了系统实际当前达到的状态
API对象
- Pod:Pod是在Kubernetes集群中运行部署应用或服务的最小单元,设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务;sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进 程(主容器)之外的工作。
- 副本控制器Replication Controller:RC是Kubernetes集群中最早的保证Pod高可用的API对象
- 副本集Replica Set:能支持更多种类的匹配模式,ReplicaSet支持集合式的selector
- 部署Deployment:部署表示用户对Kubernetes集群的一次更新操作,应用版本和 ReplicaSet 一一对应;Deployment 控制 ReplicaSet(版本),ReplicaSet 控制 Pod(副本 数)
- 服务Service:服务发现和负载均衡
- 任务Job:批处理
- 后台支撑服务集DaemonSet:要保证每个节点上都有一个此类Pod运行
- 有状态服务集StatefulSet:StatefulSet中的每个Pod的名字都是事先确定的,不能更改;适合于StatefulSet的业务包括数据库服务MySQL和PostgreSQL,集群化管理服务ZooKeeper、etcd等有状态服务
- 联邦集群Federation:支持多region
- 存储卷Volume
- 持久存储卷PV
- 节点Node
- 密钥对象Secret
- 用户账户User Account和服务账户Service Account
- 命名空间Namespace:命名空间为Kubernetes集群提供虚拟的隔离作用,Kubernetes集群初始有两个命名空间,分别是默认命名空间default和系统命名空间kube-system
- RBAC访问授权
API对象模版
apiVersion: 版本号
kind: 类型
metadata:
name: 名称
labels: 标签
xx: xx
spec:
... 各种API对象各不同
pod
spec:
containers:
env:
- name: xx
value: xx
command:
args:
images:
ports:
livenessProbe:
readinessProbe:
resources:
limits:
cpu: ""
memory: ""
requests:
volumeMounts:
- name: xx
mountPath: xx
volumes:
initContainers:
affinity:
hostAliases:
hostIPC:
hostNetwork:
hostPID:
nodeSelector:
restartPolicy:
tolerations
deployment
template:
replicas: 3
selector:
matchLabels:
xx: xx
statefulset
template:
replicas: 3
selector:
matchLabels:
xx: xx
serviceName:
volumeClaimTemplates:
Pod
理解Pod
Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器(同一个Pod中的容器会自动的分配到同一个 node 上)组合在一起共享资源。
Pod中可以共享两种资源:网络和存储。
- 每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
- 可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
使用Pod
- 很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体
- Pod不会自愈;Kubernetes使用更高级的称为Controller的抽象层,来管理Pod实例
Pod和Controller
Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力
包含一个或者多个Pod的Controller示例:
- Deployment
- StatefulSet
- DaemonSet
通常,Controller会用你提供的Pod Template来创建相应的Pod。
Pause容器
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启用pid命名空间,开启init进程。
容器探针
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。 如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。
Pod hook
Pod hook(钩子)是由Kubernetes管理的kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为Pod中的所有容器都配置hook。 Hook的类型包括两种:
- exec:执行一段命令
- HTTP:发送HTTP请求。
Initializer/PodPreset
- init容器,在应用程序容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本
- Preset 就是预设,有时候想要让一批容器在启动的时候就注入一些信息,比如 secret、volume、volume mount 和环境变量,而又不想一个一个的改这些 Pod 的 template,这时候就可以用到 PodPreset 这个资源对象了
Deployment
Deployment控制 ReplicaSet(版本),ReplicaSet控制Pod(副本数)
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续 Deployment
StatefulSet:
StatefulSet 的控制器直接管理的是Pod,每个pod不同;利用Headless Service和PV/PVC,实现了对Pod的拓扑状态和存储状态的维护。
- 稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
- 稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现
- 有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依序进行(即从 0 到 N-1,在下一个 Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现
- 有序收缩,有序删除(即从 N-1 到 0)
DaemonSet
DaemonSet 的主要作用,是让你在 Kubernetes 集群里,运行一个 Daemon Pod。 所以,这个 Pod 有如下三个特征:
- 这个 Pod 运行在 Kubernetes 集群里的每一个节点(Node)上;通过tolerations
- 每个节点上只有一个这样的 Pod 实例;
- 当有新的节点加入 Kubernetes 集群后,该Pod 会自动地在新节点上被创建出来;而当旧 节点被删除后,它上面的Pod也相应地会被回收掉。
Operator
更加灵活和编程友好的管理“有状态应用”的解决方案:自定义资源类型对应的自定义控制器
Operator 的工作原理,实际上是利用了 Kubernetes 的自定义 API 资源(CRD),来描述我们想要部署的“有状态应用”;然后在自定义控制器里,根据自定义API对象的变化,来完成具体的部署和运维工作
PV与PVC绑定
- 第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须 满足 PVC 的要求。
- 第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。
- PV与PVC延时绑定,待pod的node确定后执行绑定,避免本地存储或涉及region的存储PV与pod不在同节点导致的问题
StorageClass 对象的作用,其实就是创建 PV 的模板
Local Volume 不支持动态创建,使用前需要预先创建好 PV
Service
- Service 4层 iptables/ipvs
基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍
IPVS减少了iptables规则
外部访问机制:
- nodeport
- loadbalancer
- external name
- Ingress 7层 ingress controller
全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务;一个 Nginx Ingress Controller 为你提供的服务,其实是一个可以根据 Ingress 对象和被代理后端 Service 的变化,来自动进行更新的 Nginx 负载均衡器
Kubernetes“声明式 API”的独特之处:
- 首先,所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来“声明”,我所期 望的状态是什么样子。
- 其次,“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无 需关心本地原始 YAML 文件的内容。
- 最后,也是最重要的,有了上述两个能力,Kubernetes 项目才可以基于对 API 对象的增、 删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐 (Reconcile)过程。
k8s网络
二层:
- flannel host-gw利用下一跳地址
三层:
- flannel udp、vxlan 三层封装,由flanneld负责分配子网信息、维护主机上路由表的功能
- calico bgp(在大规模网络中实现节点路由信息共享的一种协议)
资源调度
ServiceMesh
Kubernetes 的本质是通过声明式配置对应用进行生命周期管理,而 Service Mesh 的本质是应用间的流量和安全性管理
Kubernetes 的本质是应用的生命周期管理,具体说是部署和管理(扩缩容、自动恢复、发布)
资源限制与QOS
资源限制:
- limits 上限
requests 需求
resources: limits: cpu: 1000m = 1core memory: 1000Mi = 1Gi requests: cpu: xx memory: xx
三种QOS
- guaranteed:cpu/memory必须requests==limits;高保障
- busrtable:cpu/memory requests limits不同;中,弹性
- besteffort:所有资源requests/limits都不填写;低,尽力而为
表现:
- cpu:整数guaranteed会cpu绑核
- memory:oom score从小到大-999-999
- 抢占优先besteffort
operator

- 创建kubeclient\crdclient
- 通过NewSharedInformerFactory创建关注的资源的infomer
- 创建controller, 其中包括创建event broadcast, 初始化controller(kubeclientset, informer->lister, workqueue), 为infomer添加event handler(add update del)
- controller.run, 多个goroutine执行processNextWorkItem, 从workqueue取item处理
ServiceMesh
Kubernetes 的本质是通过声明式配置对应用进行生命周期管理,而 Service Mesh 的本质是提供应用间的流量和安全性管理以及可观察性。
- Kubernetes 的本质是应用的生命周期管理,具体来说就是部署和管理(扩缩容、自动恢复、发布)。
- Kubernetes 为微服务提供了可扩展、高弹性的部署和管理平台。
- Service Mesh 的基础是透明代理,通过 sidecar proxy 拦截到微服务间流量后再通过控制平面配置管理微服务的行为。
- Service Mesh 将流量管理从 Kubernetes 中解耦,Service Mesh 内部的流量无需 kube-proxy 组件的支持,通过为更接近微服务应用层的抽象,管理服务间的流量、安全性和可观察性。
- Envoy xDS 定义了 Service Mesh 配置的协议标准。
- Service Mesh 是对 Kubernetes 中的 service 更上层的抽象,它的下一步是 serverless。
Istio 是由 Google、IBM、Lyft 等共同开源的 Service Mesh(服务网格)框架
Serverless
Serverless(无服务器架构)是指服务端逻辑由开发者实现,运行在无状态的计算容器中,由事件触发,完全被第三方管理,其业务层面的状态则存储在数据库或其他介质中。
核心技术函数计算
prometheus

helm:k8s应用管理
Spring Cloud(了解)
SpringCloud的基础功能:
- 服务治理: Spring Cloud Eureka
- 客户端负载均衡: Spring Cloud Ribbon
- 服务容错保护: Spring Cloud Hystrix
- 声明式服务调用: Spring Cloud FeignA
- API网关服务:Spring Cloud Zuul
- 分布式配置中心: Spring Cloud Config